
The web is quietly getting a new class of visitors: AI agents. Not “users” in the classic sense, but automated systems that read pages to summarize them, answer questions, and increasingly take actions (fill forms, compare products, open support tickets, or extract key facts for downstream workflows). For developers and sysadmins, that shift changes the definition of “a good web page” from something humans can navigate to something machines can reliably understand.
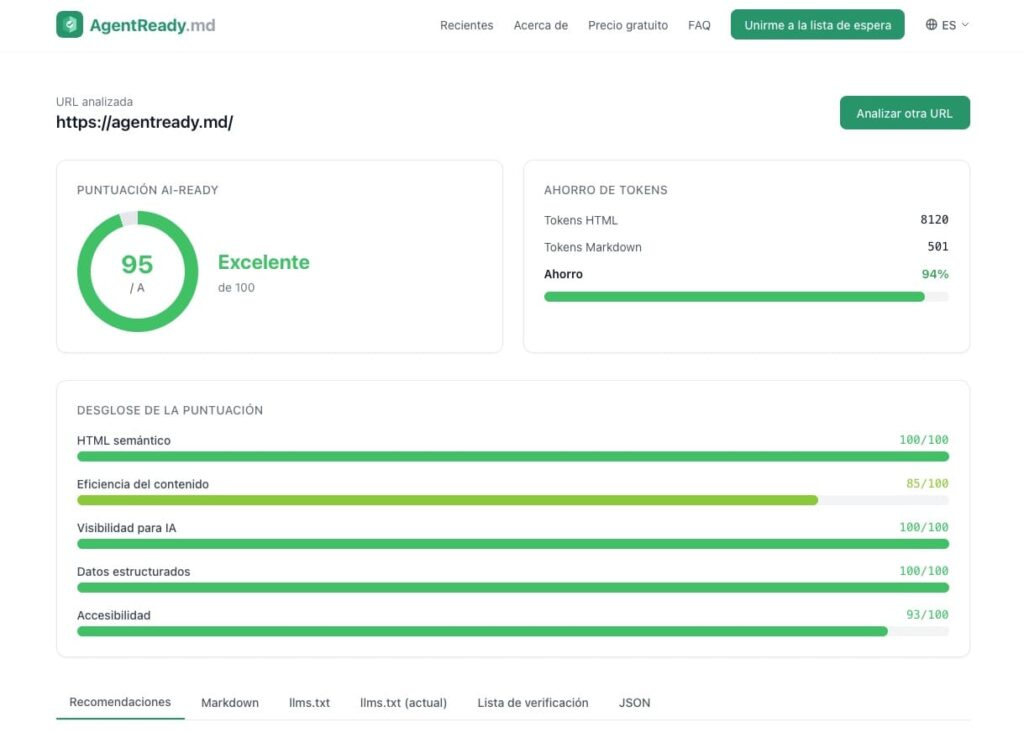
In that emerging landscape, AgentReady.md is positioning itself as a pragmatic diagnostic tool: you paste a URL, and it grades how “AI-ready” the page is—then turns the result into a prioritized to-do list. According to its own documentation, the service is free with no signup, currently in beta, and capped at 5 analyses per hour. Instead of stopping at a score, it returns a breakdown, recommendations, a Markdown conversion, and even a preview of an llms.txt guide file concept. That “actionable output” is the real value: a checklist you can hand to engineering without turning the conversation into vague debates about “AI SEO.”
Why agents struggle with the modern web
Most production websites were optimized for humans: heavy layout layers, JavaScript-driven interactions, component libraries nesting divs inside divs, and UX patterns where meaning is implied visually rather than expressed structurally.
Agents don’t “see” your page the way you do.
Depending on the tooling, an agent might:
- consume raw HTML and try to extract the “main content” heuristically,
- rely on accessibility signals (roles, labels, headings),
- render the page (expensive), then interpret what’s on-screen,
- or use a hybrid approach (DOM + vision).
That creates a new failure mode: the page looks perfect to a human, but becomes ambiguous or noisy to an agent. If a button is just an icon without a label, if content is injected late via JS, if headings are out of order, if navigation and ads outweigh meaningful text, many automated consumers end up with partial, distorted, or unusable output.
The new performance metric: tokens, not kilobytes
A parallel trend is pushing this problem from “UX nuance” into “budget line item”: token cost.
Cloudflare recently framed this in very direct terms with its Markdown for Agents feature. In Cloudflare’s own example, the same blog post reportedly weighs 16,180 tokens in HTML but 3,150 tokens when converted to Markdown—about an 80% reduction. In LLM pipelines, that gap translates into real money, faster processing, and more usable context window.
That matters because agents increasingly run at scale. A single company’s internal agent might process thousands of pages per day. A consumer-facing agent could multiply that by orders of magnitude. Even if the agent is “smart,” waste is still waste.
Two paths are converging: “AI-readiness” scoring and edge-side Markdown
This is where AgentReady.md and Cloudflare’s feature intersect.
AgentReady.md approaches the problem from the publisher side: measure readiness, reduce noise, improve semantics, and expose the right discovery signals. Cloudflare approaches it from infrastructure: if an agent asks for Markdown via Accept: text/markdown, Cloudflare can convert HTML to Markdown at the edge and return a Markdown response.
From an ops standpoint, that’s a big shift: content negotiation becomes a production concern, like gzip, caching headers, or HTTP/2 did in earlier eras.
Cloudflare’s implementation also highlights practical details sysadmins care about:
- the response can include a
Vary: acceptheader, meaning caches must treat HTML vs Markdown as different representations, - a header like
x-markdown-tokenscan indicate estimated token count, useful for downstream chunking decisions, - and Cloudflare ties the response to “Content Signals” headers that express usage preferences.
What AgentReady.md actually checks (and why it’s useful)
AgentReady.md states that it runs 21 checks across 5 weighted dimensions, producing a 0–100 score and a letter grade, plus prioritized recommendations. The breakdown is designed to stop teams from guessing where the problem is.
The five dimensions are:
- Semantic HTML (20%)
Are you using<main>,<article>, correct headings, semantic elements—meaningful structure instead of generic containers? - Content Efficiency (25%)
How much “signal vs noise” does the page contain? Does it compress cleanly into a simpler representation (like Markdown) without losing meaning? - AI Discoverability (25%)
Does the site provide signals like llms.txt, robots.txt rules, sitemap presence, and support for Markdown negotiation? - Structured Data (15%)
Are Schema.org, Open Graph, and essential meta tags present and coherent? - Accessibility (15%)
Can content be accessed without JavaScript? Is content placed early enough in the HTML? Is the page size manageable?
For engineering teams, this format is convenient because it aligns with ownership boundaries:
- frontend fixes semantics and accessibility,
- platform teams handle headers, caching, negotiation, and crawl signals,
- content teams fix structure and reduce bloat in templates,
- SEO/marketing aligns metadata and canonical strategy.
A simple table: HTML vs Markdown for agent consumption
| Dimension | HTML (typical web output) | Markdown (agent-oriented output) |
|---|---|---|
| Token footprint | Often high due to layout, navigation, boilerplate | Typically lower because structure is compact |
| Noise level | Ads, nav, cookie banners, repeated UI patterns | Cleaner “content-first” representation |
| Meaning extraction | Requires heuristics to find main content | Headings/lists/tables are explicit |
| Actionability | Forms and controls exist but may be unclear without labels | Better for reading/summarizing; actions may require separate APIs |
| Caching behavior | Default representation for browsers | Requires correct Vary behavior if negotiated |
| Failure modes | JS rendering, div soup, unlabeled controls | Lost details if conversion heuristics drop important blocks |
Markdown doesn’t replace HTML. It’s a second representation optimized for “read and reason,” not “render and interact.” But in a world where agents are reading more than humans are clicking, that second representation is quickly becoming strategic.
Practical guidance for developers and sysadmins
This is where the “AI agent” conversation becomes very operational. The fastest wins tend to be boring—and that’s the point.
1) Fix semantics before you chase new files
- Use
<main>,<article>,<nav>,<header>,<footer>properly. - Keep heading hierarchy sane (one H1, then H2, then H3…).
- Ensure buttons and inputs have accessible names (label text,
aria-label,aria-labelledbyas needed).
2) Make the content reachable without executing a whole app
AgentReady.md explicitly checks whether content works without JavaScript. That’s not nostalgia; it’s reliability. Many agents and crawlers either don’t run JS or do so imperfectly.
If your site is SPA-heavy, consider:
- SSR for primary content routes,
- pre-rendering for key informational pages,
- and ensuring critical copy exists in the initial HTML.
3) Treat content negotiation like a production feature
If you enable Markdown negotiation (whether via a CDN feature or your own stack), ensure:
- caches won’t serve Markdown to browsers or HTML to agents incorrectly,
- your monitoring includes representation-specific metrics,
- and your WAF/rate limits account for bot-style traffic.
4) Don’t ignore limitations
Cloudflare documents multiple cases where conversion won’t happen and HTML is returned instead (for example, if content-length is missing, the response is too large, or origin compression is used). That means you should validate behavior across your real routes and not assume “it’s on, so it works everywhere.”
5) Use scores as a baseline, not a vanity metric
The most valuable part of a scoring tool is not the grade—it’s the diff over time. If you treat the score like Lighthouse for agent consumption, you can prevent regressions when templates change, tag managers grow, or a redesign quietly breaks structure.
The bigger story: “AI-readiness” is becoming part of web ops
A decade ago, SEO teams argued about meta tags and page speed. Today, the argument is shifting to something deeper: how machines consume and reuse content.
AgentReady.md is an early signal of that shift because it packages a messy concept into a concrete workflow: score → recommendations → implementation snippets → re-test. Meanwhile, Cloudflare’s Markdown for Agents shows how infrastructure vendors are moving to make machine-friendly output a native capability of the edge.
For developers and sysadmins, the takeaway is blunt: semantic, accessible, efficient HTML is no longer just about compliance or good craftsmanship—it’s about staying legible in the next traffic paradigm.
FAQ
What’s the fastest way to improve “AI-readiness” without rebuilding a site?
Cleaning up heading structure, using semantic containers (main, article), labeling controls properly, and reducing template noise typically produces immediate gains because it improves both extraction quality and content efficiency.
Does serving Markdown replace SEO or standard HTML best practices?
No. Markdown is a complementary representation for machine consumers. HTML remains the canonical interface for humans and browsers, and semantic HTML still matters because it improves both accessibility and extraction quality.
Why do sysadmins need to care about this?
Because content negotiation, caching (Vary), bot traffic patterns, and edge conversion rules directly affect reliability, cost, and performance. This is drifting from “marketing concern” into “platform responsibility.”
Are AI agents guaranteed to respect robots.txt and similar rules?
Not guaranteed, but many do. AgentReady.md treats crawl/discovery signals as important because they influence whether systems can index, fetch, and reliably reuse content.