
For years, JSON has been one of those invisible technologies holding the internet together without drawing much attention. It sits inside APIs, microservices, configuration files, feature flags, dashboards, and almost every modern system that needs to exchange structured data. That is why it is tempting to overreact whenever a new format appears and declare that JSON is dead. The reality, at least for now, is much less dramatic: JSON is not dying, but it is starting to show real limitations when used as the language of exchange with large language models that charge, reason, and scale by tokens.
That is the context in which TOON has started to attract attention. TOON stands for Token-Oriented Object Notation, and the project presents itself as a compact, human-readable encoding of the JSON data model designed specifically for LLM prompts. The promise is easy to understand: keep the same objects, arrays, and primitives as JSON, but remove much of the visual and syntactic overhead that helps humans while adding cost and clutter for models.
In other words, TOON is not trying to replace JSON across all of software. It is not positioning itself as the next universal format for APIs, storage, frontends, or contracts between services. Its goal is narrower and more practical: to act as a translation layer when an application needs to send structured data to a language model. The main repository says exactly that: use JSON programmatically, and encode it as TOON for LLM input.
That logic fits the economics of generative AI surprisingly well. When an application sends data to a model, it is not really sending “objects” in the programmer’s sense. It is sending tokenized text. In that process, braces, quotes, commas, repeated field names, and other syntactic conventions that make JSON convenient for developers can turn into extra cost, extra context usage, and extra material for the model to process. That difference may feel small in a tiny payload, but it becomes much more visible when you are sending large lists, repetitive records, or long structured inputs.
TOON tries to remove noise without losing structure
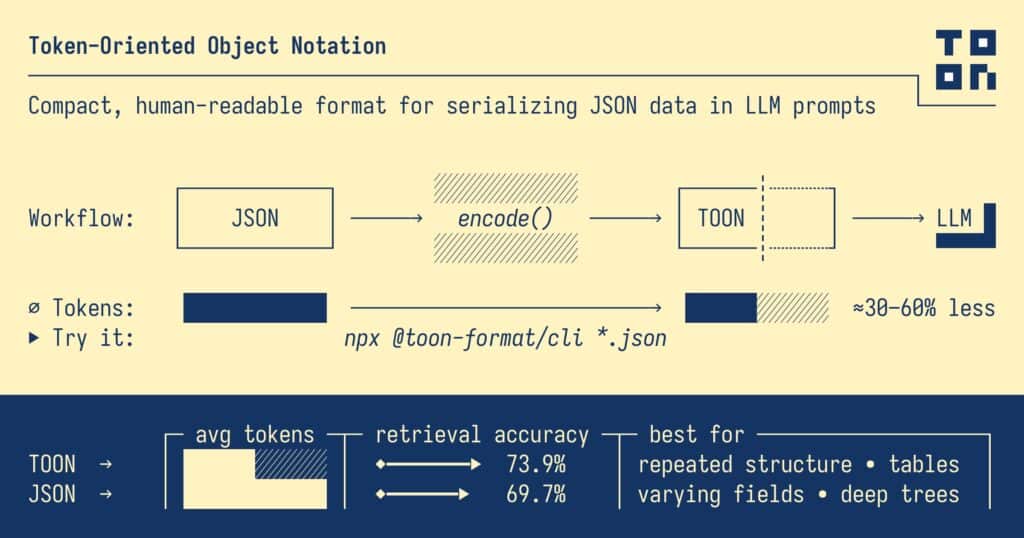
Technically, TOON combines two familiar ideas. For nested objects, it uses indentation in a YAML-like way. For uniform arrays of objects, it uses a table-like layout closer to CSV, declaring the fields once and then listing row values line by line. The result, according to the project, is a lossless representation of the same JSON data model, but with fewer tokens and a structure that is easier for LLMs to follow.
That is one of the main reasons the format has started to gain traction. It is not only about shaving off characters. It is also about making structure more explicit in a model-friendly way. On its official site, TOON claims 74% accuracy versus JSON’s 70% in mixed-structure benchmarks across four models, while using roughly 40% fewer tokens. Those numbers are clearly interesting, but they should also be treated carefully because they come from the project itself and because the benchmark focuses on structured retrieval and interpretation tasks, not on every possible LLM workflow.
That caveat matters. A later critical analysis of the TOON benchmarks argued that the published results should not be generalized too far, because they measure specific data-understanding tasks rather than proving that models “reason better” or “program better” in TOON. In other words, TOON may well be useful as a structured input format, but there is not enough public evidence to claim that it automatically improves every LLM-based system.
It is not a universal replacement for JSON
Another reason to keep expectations grounded is that the project itself acknowledges clear limits. In its main documentation, TOON says its sweet spot is uniform arrays of objects, where repeated structure allows significant token savings. It also explicitly notes that for deeply nested or non-uniform data, JSON may actually be more efficient. That means even its own authors are not arguing that TOON wins in every case.
There is also the practical issue of maturity. The format may be promising, but it is still very young compared with JSON. The official site currently lists TOON v2.1.0, while the repository references SPEC v3.0 and describes the idea as stable but still in progress. There are implementations in TypeScript, Python, Go, Rust, .NET, and other languages, but the ecosystem is still tiny compared with the decades of tooling, parser support, browser integration, database compatibility, and framework adoption that JSON already enjoys.
That puts the debate in a much more sensible place. The real question is not whether JSON will disappear. It is whether certain LLM-heavy workflows can benefit from a conversion layer that reduces token overhead and presents structure more clearly. There, TOON starts to look much more credible. A production system could keep using JSON internally, translate it into TOON only at the point where it talks to a model, and then convert responses back if needed. That does not require rewriting the whole stack. It only adds an optimization at the edge where token cost and model context actually matter.
What is really changing in the LLM era
Beyond TOON itself, the larger story is about how data formats are being reevaluated in the age of language models. For a long time, structured formats were designed mainly around human readability, parser simplicity, and interoperability across systems. LLMs introduce a new variable: the token cost of structure. That cost now affects price, latency, and context efficiency in a very direct way.
That is why the most useful headline is probably not that JSON is dying, but that JSON stops being neutral once it enters a generative AI workflow. What used to be a comfortable, good-enough format for almost everything can become verbose and unnecessarily expensive in model-facing scenarios. That does not invalidate JSON as a general standard. It simply creates room for intermediate formats that are more compact and more consciously designed for models.
Whether TOON becomes one of those formats or ends up as an influential experiment is still an open question. Right now, the most responsible way to describe it is as a serious and potentially useful idea for specific scenarios, not as the universal heir to JSON. Software rarely abandons a foundational format overnight. What it usually does is build new layers around it when the rules of the game change. And AI is very clearly changing those rules.
FAQ
What is TOON and what is it for?
TOON, or Token-Oriented Object Notation, is a format that encodes the same JSON data model with less syntactic noise and a stronger focus on reducing tokens in prompts sent to LLMs.
Does TOON replace JSON in APIs and microservices?
No. The project presents TOON as a translation layer for model input, not as a universal replacement for JSON across all software systems.
How much token reduction does TOON claim compared with JSON?
The official site claims roughly 40% fewer tokens in mixed-structure benchmarks, alongside a modest accuracy improvement in the project’s own tests.
Are there cases where JSON is still better than TOON?
Yes. TOON’s own documentation says that for deeply nested or non-uniform data, JSON may be more efficient.