
In a world dominated by SaaS monitoring services like UptimeRobot, Better Uptime or Pingdom, another trend is gaining traction: taking back control with open-source, self-hosted tools that plug directly into each company’s observability stack. That’s exactly where Kuvasz comes in — a free project that targets uptime and SSL monitoring… with ambitions that go far beyond that.
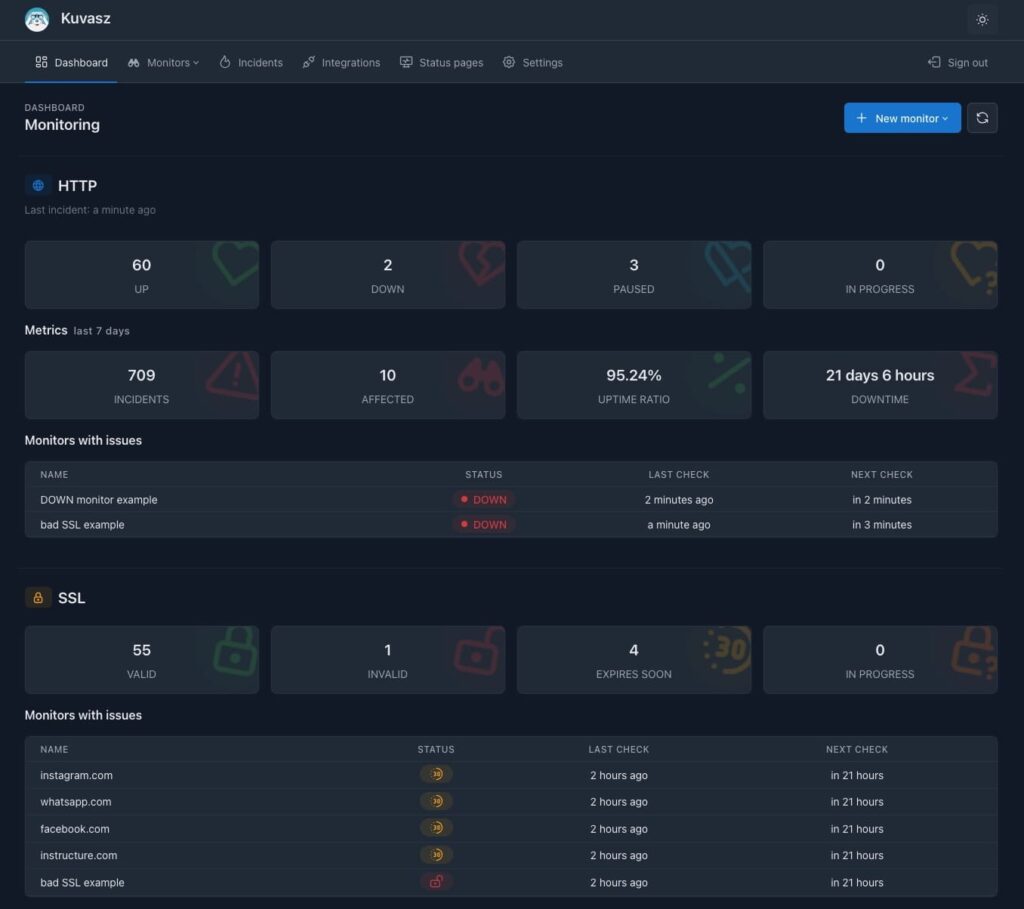
Kuvasz describes itself as an uptime and SSL monitoring service with status pages, designed to be deployed on the user’s own infrastructure. It’s not “just another pretty dashboard” on top of basic pings: it offers a modern UI, a full REST API, metric exporters, multiple notification channels, and even declarative configuration via YAML.
What Kuvasz is and what it aims to replace
The project itself doesn’t shy away from the comparison: Kuvasz vs. UptimeRobot.
While UptimeRobot follows a freemium SaaS model, Kuvasz focuses on:
- Open source and self-hosting
- HTTP(S) and SSL monitoring with fine-grained controls
- Status pages (public or private) to communicate incidents
- Multiple alerting channels: email, Discord, Slack, Telegram, PagerDuty and more
- A full REST API to manage monitors and integrate with other systems
- Prometheus and OpenTelemetry exporters, making it a first-class citizen in modern observability stacks
The idea is clear: deliver something that, feature-wise, can match (or surpass) many commercial solutions, but with the freedom to deploy it wherever the user wants — on their own servers, in Kubernetes, on a private cloud provider or even a small VPS.
5-second checks and unlimited monitors
One of the most striking lines in the comparison table is the monitoring frequency:
- Kuvasz: checks every 5 seconds
- UptimeRobot Free: every 5 minutes
- UptimeRobot Solo (paid): every 60 seconds
On top of that, Kuvasz doesn’t impose a hard limit on monitors: it advertises “unlimited” monitoring, versus 50 checks in UptimeRobot’s free plan or 10 in its Solo plan. Of course, in a self-hosted setup the real limit is the resources you assign to the service, but the philosophy is clear: the user shouldn’t be fighting against artificial caps.
The tool also supports:
- HTTP(S) monitoring with:
- keyword matching,
- header matching,
- slow response alerts,
- custom HTTP methods,
- custom headers and request bodies,
- custom status matchers to decide what’s “OK”.
- SSL certificate monitoring, to catch expirations before they take production services down.
- Heartbeat (push) checks, aimed at jobs and cron tasks that report their own health.
Some features, like ICMP ping monitoring, Microsoft Teams integration, webhooks or SMS, are marked as “📆 planned”, which suggests an active roadmap.
Status pages: for your users… or just for your own team
Kuvasz ships with configurable status pages, designed both for:
- Public communication about the state of SaaS products, APIs, customer portals, etc.
- Private internal pages, useful for support teams, NOCs or engineering.
Compared to the limits imposed by some SaaS offerings (for example, 1 status page on free tiers or 3 on certain paid plans), Kuvasz proposes a more flexible model, fully under the user’s control and without upgrade walls.
Notifications: from email to PagerDuty, via Discord
Alerts are one of the most critical parts of any monitoring platform. Today, Kuvasz supports:
- Discord
- Slack
- Telegram
- PagerDuty
And it plans to add:
- Microsoft Teams
- Generic webhooks
- SMS / voice calls (via external providers that the user pays for separately).
Per-monitor configuration allows you to tune:
- which channel is used for each service,
- which team gets which type of incident,
- and how technical monitoring is blended into each company’s existing communication flows (for example, internal incidents on Discord/Slack only, critical events via PagerDuty).
Prometheus and OpenTelemetry integration
For DevOps and SRE profiles, one of the most interesting angles is the support for:
- Prometheus exporters
- OpenTelemetry exporters
This positions Kuvasz closer to an integrated observability component than to a simple “ping website”. It enables:
- feeding uptime metrics into existing Grafana dashboards,
- correlating latency and availability with app and database metrics,
- building combined alerts based on multiple data sources.
For teams already invested in Prometheus, Loki, Tempo or other CNCF tools, this ability to export metrics means Kuvasz fits naturally into the bigger picture, without forcing a change of primary monitoring stack.
Infrastructure as Code: YAML-based configuration
The project also mentions Infrastructure as Code (IaC) support via YAML, which opens some powerful workflows:
- Defining monitors, status pages and configuration in version-controlled Git files
- Reviewing changes through pull requests before touching critical monitors
- Reproducing environments consistently across staging, pre-prod and production
In a world where many companies have already moved infrastructure, deployments and even firewall rules to code, having monitoring defined in YAML as well reduces the chaos of click-configured dashboards.
Typical scenario: from free UptimeRobot to self-hosted Kuvasz
For small projects, UptimeRobot or similar services are “good enough”: a few HTTP checks, some pings and email alerts. But as infrastructure grows, hard limits start to bite:
- number of monitors,
- check frequency,
- number of status pages,
- lack of metric exporters,
- dependence on a third-party service to know whether your own service is down.
At that point, Kuvasz becomes attractive for:
- Companies with technical teams and a DevOps culture, who prefer to self-host critical monitoring.
- Hosting and cloud providers who want to offer status dashboards to their customers on top of their own infrastructure.
- Open-source projects that value transparency with public status pages and don’t want to rely on an external SaaS just to report outages.
Of course, self-hosting also means taking responsibility for:
- deployment (for instance, via Docker),
- monitoring Kuvasz itself,
- backups and updates.
But in exchange you gain:
- full control over data and retention,
- freedom to integrate with any system,
- no artificial limits dictated by commercial plans.
A Hungarian guard dog as a metaphor
The name Kuvasz isn’t random: it refers to an ancient Hungarian breed of livestock and guard dog. It’s an obvious metaphor for what the project wants to be:
a “watchdog” for your services, keeping an eye on uptime and certificates, barking when something goes wrong and showing the world (or your team) how your infrastructure is doing.
In a landscape where many solutions drift toward locked-down, subscription-only models, projects like Kuvasz are a reminder that it’s still possible to combine:
- a modern experience,
- with open-source code,
- and full ownership of your monitoring stack.
For sysadmins, DevOps teams and infrastructure providers, it’s at least worth a test run in a lab environment — the next “guard dog” for their platform might already be just a container away.