
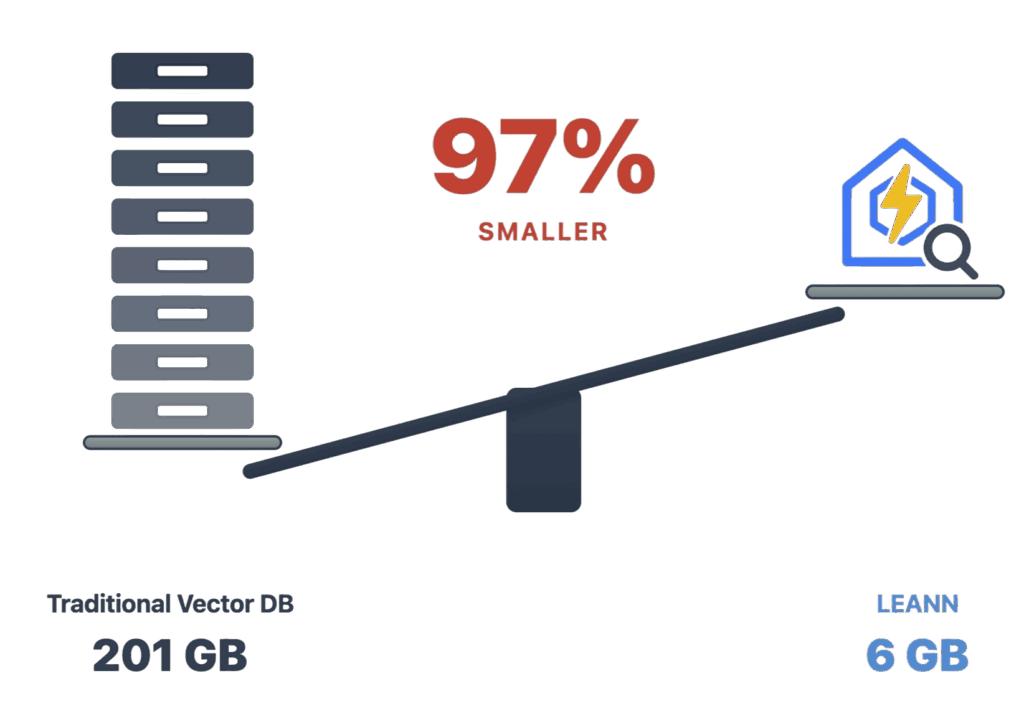
One of the biggest hidden costs in retrieval-augmented generation is not the model itself, but the storage burden of the vector index sitting underneath it. That is the problem LEANN is trying to solve. The open-source project describes itself as “the smallest vector index in the world” and says it can shrink a 60 million text-chunk index from 201 GB to 6 GB, while keeping search quality intact enough for practical RAG workloads on personal devices.
The pitch is easy to understand, and that is part of why the project has attracted so much attention. Instead of forcing users to run a heavyweight vector database that stores all embeddings up front, LEANN uses what its authors call graph-based selective recomputation with high-degree preserving pruning. In plain terms, it stores a much lighter graph structure and recomputes embeddings only when needed during search, rather than keeping the full embedding store on disk all the time.
That design choice matters because storage has become one of the main blockers for local RAG. According to the LEANN repository, a traditional vector database would need about 3.8 GB for a DPR-scale dataset of 2.1 million chunks, 201 GB for a 60 million-chunk wiki-style dataset, 1.8 GB for 400,000 chat chunks, 2.4 GB for 780,000 email chunks, and 130 MB for 38,000 browser-history entries. LEANN lists the corresponding footprints as 324 MB, 6 GB, 64 MB, 79 MB, and 6.4 MB respectively. That is the basis for the repo’s repeated “97% savings” claim.
The academic paper behind the project makes the case in more measured terms. It says LEANN can reduce storage to less than 5% of the original dataset size, while still achieving over 90% top-3 recall within two seconds in its evaluations. That is slightly more cautious than the repository’s “without accuracy loss” phrasing, but it still points to the same conclusion: the system appears to trade storage for selective recomputation in a way that can keep retrieval quality high enough for real use.
That distinction is important. LEANN is not claiming to break the laws of physics. It is moving some of the cost from permanent storage into search-time computation. For many edge and personal-device scenarios, that trade-off makes a lot of sense. A laptop user may be perfectly happy to spend a bit more CPU during retrieval if it means avoiding a giant index that eats hundreds of gigabytes of disk.
The project is also trying to make that architecture useful outside benchmark papers. The GitHub repository presents LEANN as a personal RAG stack that can work across documents, PDFs, email, browser history, WeChat, iMessage, ChatGPT exports, Claude exports, Slack via MCP, Twitter bookmarks, and codebases. It also includes CLI tooling, MCP integration for Claude Code, AST-aware code chunking, metadata filtering, and support for both HNSW and DiskANN backends.
That broader ambition may be just as important as the compression numbers. LEANN is not only saying “we made vector indexes smaller.” It is saying “we made local semantic search practical enough to become a personal AI memory layer.” The repository explicitly frames the project as a way to “transform your laptop into a powerful RAG system” that can search millions of documents while keeping data on-device.
There is, however, one claim that needs a bit of caution: privacy. The repository repeatedly says LEANN enables “zero cloud costs and complete privacy,” and it recommends local setups such as Ollama for full privacy. But the same project also supports external generation providers including OpenAI, Anthropic, and other OpenAI-compatible APIs. So LEANN can absolutely be run locally and privately, but whether it actually is depends on the user’s configuration choices.
The paper also helps explain why this is not just another lightweight vector store with a nicer README. LEANN’s core techniques include selective recomputation, graph pruning that preserves hub nodes, and a two-level search strategy. In effect, it tries to preserve the most useful parts of the search graph and recompute the rest only when a query path justifies it. That is what allows it to cut storage so aggressively without collapsing retrieval quality.
In the current AI tooling landscape, that makes LEANN more than a neat optimization. It points to a broader trend: RAG systems are moving closer to the device, and the bottleneck is no longer just model size or inference speed. Storage efficiency is becoming a strategic problem too. If LEANN’s approach holds up in wider real-world use, it could make local retrieval far more realistic for researchers, developers, and privacy-conscious users who want personal AI systems without enterprise-grade storage overhead.
The result is not magic, and it is not a universal guarantee that every RAG setup will instantly become tiny and perfect. But as an engineering direction, LEANN is compelling. It suggests that the future of personal AI may depend not only on better models, but on much smarter indexes.