
Proxmox VE has earned a solid reputation as a pragmatic virtualization platform: flexible, relatively lightweight, and increasingly common in SMBs, labs, service providers, and even larger production environments. But as Proxmox-based estates grow, many operators encounter the same inflection point: what was manageable with the native UI, a few scripts, and tribal knowledge becomes harder to standardize when infrastructure spans multiple clusters, mixed hardware generations, different storage backends, and teams with distinct responsibilities.
That is the operational gap PegaProx is positioning itself to fill. Presented as an “enterprise Proxmox management platform,” PegaProx aims to centralize day-to-day operations for modern Proxmox VE data centers into one consistent interface—mirroring the unified control-plane experience that administrators often associate with established enterprise virtualization suites.
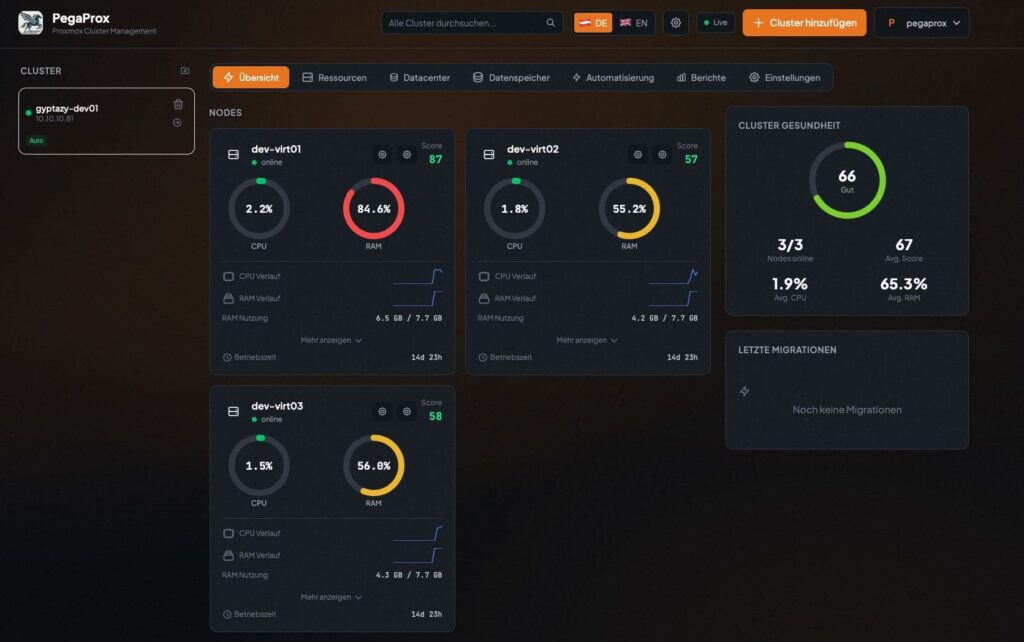
According to documentation published on January 25, 2026, PegaProx is designed as a “real datacenter manager,” not just a monitoring dashboard. Its promise is to reduce operational complexity while keeping operators in control of clusters, nodes, storage, and workloads—without forcing administrators to jump between separate tools, cluster views, and ad-hoc workflows.
A Unified Control Plane for Multi-Cluster Operations
In most Proxmox environments, complexity does not arrive all at once. It accumulates. A second cluster is added for a new site, a new rack, or a different tenant. Hardware gets replaced in phases, which introduces CPU feature mismatches. Storage expands organically: local disks here, shared storage there, replication policies evolving over time. Meanwhile, change management becomes more formal, and “who can do what” starts to matter as more people touch the platform.
PegaProx’s central pitch is simple: treat multiple Proxmox clusters as a coherent operational surface. The platform highlights a set of capabilities that will sound familiar to operators who have managed large virtualization estates:
- Unified multi-cluster management
- Node and cluster monitoring with real-time metrics
- User, group, and tenancy management with granular access control
- Semi-automated node security patch management
- Cross-cluster migration workflows
- Virtual machine and container management from one interface
- CPU alignment across nodes to enable safer VM live migrations
- Intelligent load balancing for VMs
- Intelligent load balancing for storage
- High availability and failover tooling
The common theme is operational standardization: policy-driven actions, centralized visibility, and fewer manual steps that depend on individual operator habits.
Why CPU Compatibility Becomes a Defining Pain Point
One of the most practical—and often underestimated—challenges in real-world clusters is CPU heterogeneity. Proxmox deployments rarely remain perfectly uniform over time. New nodes arrive with newer CPU generations and instruction sets. Older nodes remain online to extend refresh cycles. Mixed Windows and Linux workloads impose additional constraints, and “host CPU” settings can become a risky default when live migration is expected to be reliable.
PegaProx claims to address this by automatically detecting CPU features across nodes and determining a safe baseline CPU type that remains compatible across the cluster. The intention is to make live migration predictable by reducing guesswork and eliminating trial-and-error validation.
For many operators, this is not a cosmetic feature. It is the difference between “live migration as an everyday tool” and “live migration as a maintenance-time gamble.” If implemented well, CPU compatibility automation can materially reduce downtime risk, shorten maintenance windows, and make mixed-hardware clusters less fragile.
Patch Management: The Reality of API Gaps and SSH-Based Operations
Patch management is another area where Proxmox operators often improvise. Some teams lean on configuration management tools like Ansible. Others use custom scripts and runbooks. In many cases, the native tooling shows pending updates but does not provide a cohesive, centralized workflow for controlled patching across fleets.
PegaProx’s documentation suggests it can surface pending node updates and allow upgrades to be executed directly from its interface. To do that, it relies on SSH access to Proxmox nodes—explicitly acknowledging that certain operational actions are not fully available via the Proxmox API.
That design choice has trade-offs. On one hand, it enables a more complete “single pane of glass” experience that reduces tool switching and manual steps. On the other, it increases the importance of hardening: key management, network segmentation, auditability, least-privilege access, and careful operational controls around maintenance windows and rollback strategies.
From an enterprise operations standpoint, centralized patch execution is valuable only if it is paired with guardrails. PegaProx’s direction suggests an attempt to bring “structured maintenance” to Proxmox estates that have outgrown informal node-by-node updating.
Live Migration Across Clusters: A Workflow, Not a Button
Live migration is frequently treated as a capability that either works or does not. In practice, migration reliability depends on dozens of details: storage reachability, attached ISOs, network alignment, configuration flags, and consistency in the target environment.
PegaProx positions live migration as a guided operational workflow. The platform claims it can proactively detect common migration blockers and surface clear warnings before a migration is initiated. The goal is to reduce “fail late” scenarios—where a migration attempt only reveals issues mid-flight—by turning migrations into a more predictable, validated operation.
If that approach holds up in production, it would directly address one of the most common frustrations in larger Proxmox estates: migrations that fail not because the platform is incapable, but because the operational state around it was not validated consistently.
Multi-Tenancy and Access Control: From “Admins” to Teams
As Proxmox environments become shared platforms—across departments, customers, or internal teams—access control often becomes a structural requirement. PegaProx emphasizes support for users, groups, and tenancies, with fine-grained permissions that can be scoped to clusters, nodes, or even individual VMs.
This matters because role-based access control is rarely just about security. It is also about operational clarity: who is responsible for which workloads, who can migrate what, who can patch nodes, and how changes are controlled. A strong tenancy model can turn a Proxmox estate from “a cluster run by a few experts” into a scalable platform operated by multiple teams without constant privilege escalation.
Deployment Direction: Container vs VM Appliance
PegaProx is described as still evolving and not yet released as a public general-availability product, with no source code published at this stage. The planned distribution model is presented as ready-to-use images that can be imported into Proxmox environments.
Two deployment options are described:
- A lightweight container-based deployment, focused on minimal overhead and fast setup.
- A VM-based appliance (planned on Ubuntu) designed to support live migration and more “production-friendly” operational continuity for the management plane itself.
This distinction reflects a well-known limitation: container live migration is constrained by underlying technologies not universally enabled in typical Proxmox setups. In environments where the management platform must be highly available and maintenance-friendly, a VM-based control plane often aligns better with enterprise expectations.
A Signal of Maturity in the Proxmox Ecosystem
Whether PegaProx becomes widely adopted will depend on execution: robustness under load, security posture, compatibility across diverse Proxmox deployments, and how well it delivers on the promise of standardization without constraining flexibility.
Still, the direction is telling. The Proxmox ecosystem is increasingly moving toward the same expectations operators bring to enterprise virtualization: policy-driven scheduling, consistent access control, guided migration workflows, and centralized maintenance operations. PegaProx is betting that Proxmox users are ready for a management layer that makes “running Proxmox at scale” feel less like craftsmanship and more like disciplined operations.
FAQ
What problem does PegaProx solve for Proxmox VE operators?
It aims to unify multi-cluster operations—monitoring, VM management, migration workflows, access control, and node maintenance—into one consistent interface to reduce operational overhead and fragmented tooling.
Why is CPU compatibility (“CPU alignment”) critical for reliable live migration?
In mixed-hardware clusters, different CPU generations expose different instruction sets. Without a safe baseline CPU configuration, live migrations can fail or cause instability, especially in mixed Windows/Linux estates.
How does centralized patch management change Proxmox operations?
It can standardize maintenance across many nodes, reduce manual steps, and improve repeatability—provided it is implemented with strong controls (maintenance windows, approvals, audit logs, and secure access handling).
Is PegaProx intended only for large enterprises?
The positioning suggests it targets both growing labs and production environments, especially where multiple clusters, teams, and operational policies are required. The value increases as environments become distributed and harder to manage manually.