
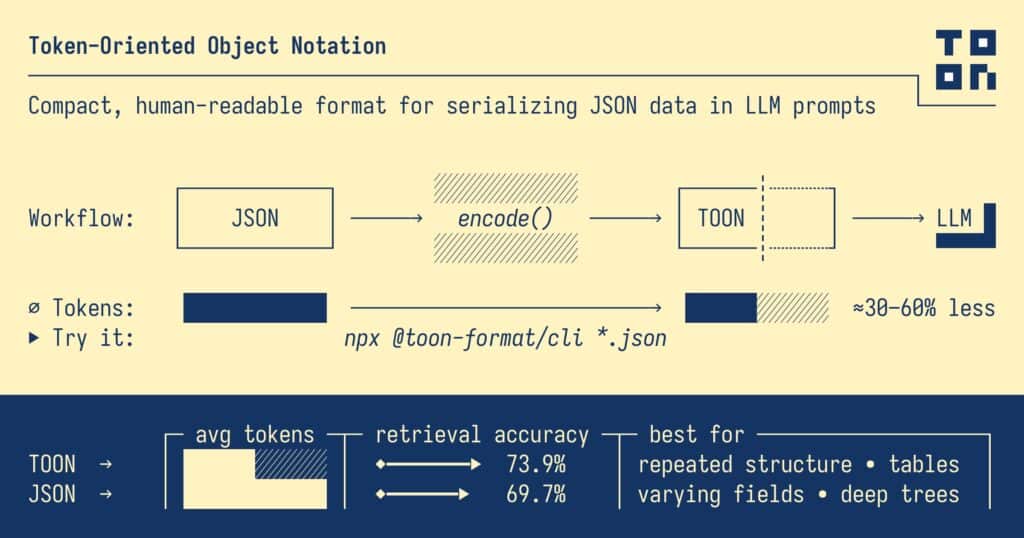
The Large Language Model ecosystem has been looking for ways to pack more data into fewer tokens. JSON is the de facto standard for representing complex structures, but it’s also noisy, repetitive, and expensive when sent to an LLM. That’s exactly the problem TOON (Token-Oriented Object Notation) sets out to solve: an open format designed specifically for AI prompts that promises to cut token costs and improve model comprehension without giving up JSON’s structure.
The project, published as open source under the MIT license, comes with a formal specification, detailed benchmarks, and a TypeScript SDK. The core idea is simple: keep using JSON in your code… and translate it to TOON right before sending it to the model.
From Verbose JSON to Compact TOON
The starting point is familiar. A basic users object in JSON looks like this:
{
"users": [
{ "id": 1, "name": "Alice", "role": "admin" },
{ "id": 2, "name": "Bob", "role": "user" }
]
}
Code language: JSON / JSON with Comments (json)YAML cuts some syntactic noise:
users:
- id: 1
name: Alice
role: admin
- id: 2
name: Bob
role: user
TOON pushes the idea further:
users[2]{id,name,role}:
1,Alice,admin
2,Bob,user
In a single header, it declares:
- The collection name (
users). - The number of items (
[2]). - The fields for each row (
{id,name,role}).
Below that, each line is just a data row separated by a delimiter (comma, tab, or pipe). For an LLM, this representation is shorter and easier to follow at the same time: the model knows how many rows to expect, which fields each row has, and in which order.
What TOON Actually Is
At its core, TOON is an alternative serialization of JSON optimized for prompts:
- It uses YAML-style indentation for nested objects.
- It adopts a tabular layout for uniform arrays of objects (traditional “records” tables).
- It keeps JSON’s mental model: conversions between both are lossless.
- It trims syntax to the minimum: fewer braces, brackets, and quotes.
Its “sweet spot” is uniform arrays of objects: large collections where all elements share the same structure. In those cases, the authors report token savings of 30–60 % compared to pretty-printed JSON and a clear boost in how reliably models retrieve data.
For very deeply nested or non-uniform structures, the project itself acknowledges that JSON (especially compact/minified) can still be more efficient.
When You Shouldn’t Use TOON
The maintainers are quite explicit about the limits:
- Deeply nested configurations or highly heterogeneous fields: the tabular format stops applying and TOON loses many of its advantages.
- Semi-structured arrays, with only ~40–60 % “tabular eligibility”: token savings over JSON shrink, and extra complexity may not be worth it.
- Pure flat tabular data: CSV is still smaller. TOON adds a small overhead (~5–10 %) in exchange for structure and validation.
- Ultra latency-sensitive scenarios: fewer tokens don’t always mean lower latency; you should benchmark in your actual deployment.
The philosophy is pragmatic: TOON doesn’t try to replace JSON or CSV everywhere, but to occupy a very specific niche where the trade-off between tokens, structure, and reliability clearly favors this new format.
What the Benchmarks Say: Fewer Tokens, More Correct Answers
The TOON repo includes a benchmark suite with 209 data-retrieval questions over several datasets and four different models. The “efficiency” ranking combines accuracy with token cost.
Overall Efficiency by Format
(accuracy per 1,000 tokens on the full dataset)
| Format | Accuracy | Tokens Used | Efficiency Index |
|---|---|---|---|
| TOON | 73.9 % | 2,744 | 26.9 |
| JSON compact | 70.7 % | 3,081 | 22.9 |
| YAML | 69.0 % | 3,719 | 18.6 |
| JSON | 69.7 % | 4,545 | 15.3 |
| XML | 67.1 % | 5,167 | 13.0 |
The standout figure: TOON achieves 73.9 % accuracy versus JSON’s 69.7 %, while using 39.6 % fewer tokens in these experiments.
Looking at individual models, the pattern holds:
- On smaller models like claude-haiku or grok-4-fast, TOON tops the table or ties with compact JSON, with several extra accuracy points.
- On stronger models like gemini-2.5-flash or gpt-5-nano, TOON stays near the top:
- gpt-5-nano reaches 90.9 % accuracy with both TOON and compact JSON, above classic JSON (89.0 %).
- gemini-2.5-flash climbs to 87.6 % with TOON, ahead of JSON and YAML.
In the “mixed-structure” track (nested and semi-structured data), TOON cuts token counts by roughly 21.8 % versus JSON overall, though compact JSON is still slightly smaller on some low-tabularity datasets. In the flat track, CSV remains king in size, but TOON is only about 6 % larger while offering much richer structure.
Syntax: Less Noise, Same Information
The TOON spec introduces a number of ideas aimed at making models’ lives easier:
- Explicit array lengths:
items[3]tells the model up front how many rows to parse. - Field headers for tabular arrays:
items[2]{sku,qty,price}:declares the shape once. - Configurable delimiter: comma, tab (
\t), or pipe (|), so you can tune tokenization further. - Optional “key folding”: single-key nesting chains can be collapsed into dotted paths (for example,
data.metadata.items[2]: a,b) to reduce indentation while still being able to reconstruct the original JSON. - Smart quoting rules: only quote what’s necessary; strings that look like numbers, booleans, or
nullare forced into quotes to avoid misinterpretation.
The result reads like a hybrid between YAML and CSV, but with clear guarantees that you can always round-trip back to proper JSON.
Implementations and Tooling: Ready to Use
TOON is shipped with an official CLI and a TypeScript library:
- Quick conversion from the command line:
# JSON → TOON npx @toon-format/cli data.json -o data.toon # TOON → JSON npx @toon-format/cli data.toon -o data.jsonYou can pick the delimiter, see token savings (--stats), or enable key folding (--key-folding safe). - TypeScript/JavaScript SDK:
import { encode, decode } from '@toon-format/toon' const data = { users: [ { id: 1, name: 'Alice', role: 'admin' }, { id: 2, name: 'Bob', role: 'user' } ] } const toon = encode(data) const backToJson = decode(toon)
On top of that, there are implementations (some official, some community-maintained) in .NET, Go, Python, Rust, Java, Kotlin, Ruby, PHP, Swift, and more, making it easier to plug TOON into existing pipelines.
How to Use TOON With LLMs
The practical guidance is:
- For input: wrap TOON data in a fenced code block, for example:
```toon users[3]{id,name,role}: 1,Alice,admin 2,Bob,user 3,Charlie,userThe model can then navigate the table and answer data-retrieval questions more reliably. - For output: show the model a header template and spell out clear rules—row count, delimiter, indentation, and no text outside the code block. That makes generating structured tables much more predictable.
Will TOON Replace JSON?
The authors’ stance is more pragmatic than revolutionary: TOON is not meant to replace JSON for storage, APIs, or configuration, but to act as a prompt-time translation layer optimized for LLMs.
For teams working with large contexts, RAG, analytics, or big tables in prompts, TOON offers three big advantages:
- Fewer tokens for the same information.
- More explicit, verifiable structure, which reduces errors when reading or generating data.
- A nicer balance between compactness and human readability compared to minified JSON or plain CSV.
In a world where every token matters—for cost, speed, and context clarity—many teams will likely at least experiment with adding TOON as one more tool in their LLM data toolbox.
Frequently Asked Questions About TOON
What does TOON offer over JSON in LLM prompts?
TOON cuts syntactic noise and key repetition, especially in large, uniform arrays. That translates into fewer tokens and a structure that’s easier for models to track, with explicit array sizes and field headers. The published benchmarks show several extra accuracy points compared to JSON while using significantly fewer tokens.
When is JSON or CSV still the better choice?
JSON remains preferable for deeply nested structures, complex configurations, and non-uniform data, where TOON’s tabular mode doesn’t kick in. CSV, on the other hand, is still the most compact option for completely flat tables with no nesting. TOON sits in between: slightly bigger than CSV, but with enough structure for LLMs to handle and validate data more robustly.
How do I integrate TOON into an existing JSON-based application?
The typical pattern is to keep JSON as your internal and API format, and convert to TOON right before calling the LLM. With the CLI or TypeScript SDK, you can automate JSON → TOON and TOON → JSON conversions, adding options like custom delimiters or key folding. That way, you get the prompt-side benefits without touching your core application logic.
Is TOON suitable as a storage format or for designing APIs?
The project itself advises against using TOON as a drop-in JSON replacement for persistent storage or public APIs. It’s designed for communication with LLMs, where tokenization and model readability matter more than ecosystem compatibility. For databases, REST APIs, or service-to-service messages, JSON, Protobuf, and similar formats are still the standard choices.
More information in github.com.