
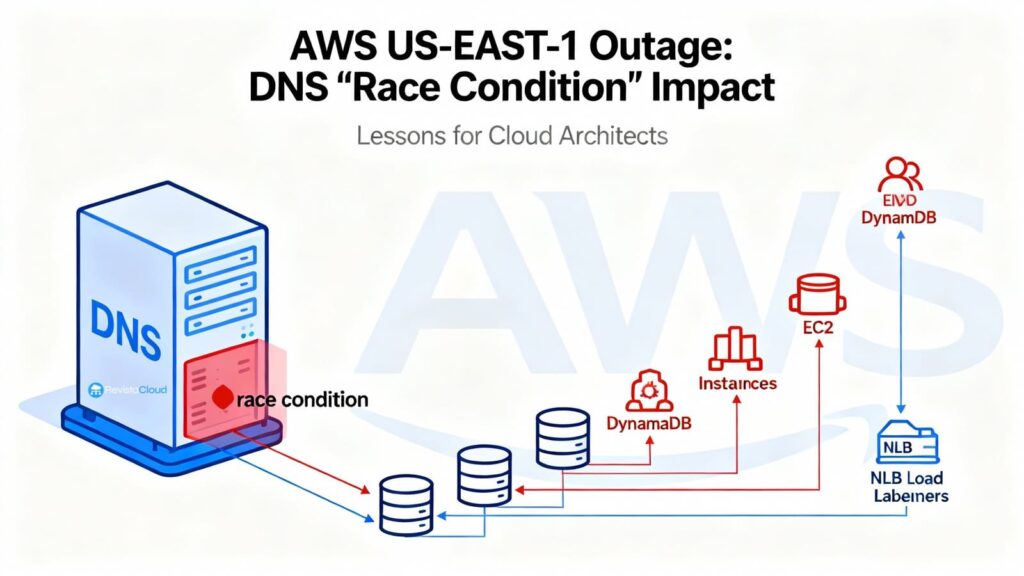
The AWS N. Virginia (us-east-1) interruption on October 19–20 did more than set off pagers: it exposed how fragile an architecture can be when the control plane depends on a central “catalog” and that catalog vanishes overnight. Amazon’s post-mortem points to a root cause that any SRE will recognize: a race condition in DynamoDB’s internal DNS automation. The system ended up applying an empty DNS plan to the regional endpoint (dynamodb.us-east-1.amazonaws.com), and self-healing got stuck. From there, IAM, STS, EC2, Lambda, NLB, ECS/EKS/Fargate, Redshift and others cascaded into errors for hours.
For sysadmin teams, the key is not just what broke, but why it propagated and what to change on Monday morning to withstand the next incident—whether in AWS or any other cloud.
“This isn’t about demonizing a region. It’s about designing to lose a region and, at times, to lose your coordination point. If the ‘catalog’ dies, can your business still serve traffic?”
— David Carrero, co-founder of Stackscale (grupo Aire), a European private cloud built on VMware and Proxmox.
What Actually Happened (Operator’s View)
DynamoDB maintains hundreds of thousands of DNS records per region to steer traffic to a heterogeneous fleet of load balancers and variants (public, FIPS, IPv6, account-specific endpoints, etc.). Two internal components govern this complexity:
- DNS Planner: periodically computes a DNS plan per endpoint (set of LBs + weights) based on capacity and health.
- DNS Enactor: applies the plan in Amazon Route 53 using atomic transactions. For resiliency, there are three Enactors, one per AZ, running independently and in parallel.
The fatal sequence was all about timing: a badly delayed Enactor finished applying an old plan just as another, up-to-date Enactor had finished applying the new plan and was cleaning up stale generations. Outcome: the old plan overwrote the new one, and the cleanup deleted that old plan as “too old,” leaving the endpoint with no IPs and the system in an inconsistent state that blocked further automatic fixes. Manual intervention was required (stop the automation, restore correct DNS state, unblock the cycle).
That DNS vacuum immediately cut off new connections to DynamoDB. With the “catalog” down, the control plane degraded:
- EC2: once DynamoDB came back, the DropletWorkflow Manager (DWFM) attempted to re-establish millions of leases with physical servers (“droplets”) and entered congestive collapse; the remedy was throttling + selective restarts to drain queues and normalize.
- Network Manager: accumulated a backlog of network-state propagations for new instances; many instances booted without connectivity until their configuration arrived.
- NLB: health checks saw flapping nodes (no network yet), triggering aggressive AZ failovers and capacity removals; AWS disabled automatic AZ DNS failover temporarily and re-enabled it after the network stabilized.
Everything else reflected the same picture: Lambda prioritizing synchronous invocations and limiting event sources, ECS/EKS/Fargate with blocked launches, STS with latency, and Redshift clusters stuck in “modifying” when they couldn’t replace hosts.
What Matters for a Sysadmin: Patterns That Broke, Patterns That Save You
1) Don’t Just Design for Losing an AZ—Design for Losing the “Catalog”
This hit the heart of the control plane. Even if the data plane remains relatively healthy, if you can’t launch instances, propagate networking, issue credentials, or resolve an endpoint, you lose your hands.
Action: consciously separate “serve traffic” from “manage resources.” Can your app run for hours without autoscaling, with pre-allocated capacity or a warm pool?
“We talk a lot about multi-AZ, but what saves you in events like this is operational multi-region and hot capacity so you can ride out a control-plane brownout.”
— David Carrero (Stackscale)
2) DNS: Buffer with Cache (Avoid Extremes)
DNS caching buffers brief resolution blips; excessively long TTLs can delay provider fixes.
Action: set moderate TTLs in resolvers (neither 0 seconds nor days), exponential backoff + jitter in critical clients, and never hard-code IPs of managed services.
3) Health Checks with Grace—Avoid Flapping
Bringing nodes into service before networking is propagated causes false negatives and aggressive failovers.
Action: add thresholds, grace periods, and velocity limits on capacity removal. During mass rollouts, temporarily relax evaluation windows.
4) Circuit Breakers & Functional Degradation
If you can’t persist to DynamoDB, can you switch to read-only? If you can’t create resources, can you pause non-critical features and buffer locally?
Action: implement clear degrade paths and service-level circuit breakers (and metrics to trigger them).
5) STS/IAM: Staggered Expirations
Don’t let your entire fleet renew tokens simultaneously amid latency spikes.
Action: stagger rotations, use grace windows, and apply jittered retries.
6) Runbooks & Game Days: “us-east-1 Is Out”
Document exactly what to switch off, what to prioritize, who does what, and how to shift DNS/Region.
Action: run realistic game days: no new launches, no STS, “nervous” NLB.
“What If My Business Can’t Afford Multi-Region in Public Cloud?”
Many European sysadmin teams adopt a hybrid strategy: public cloud where it shines, private cloud where control, data sovereignty, and predictability matter most.
“We operate VMware and Proxmox clusters in Europe for companies that want resilience and sovereignty: controlled latencies, clear SLAs, and the ability to replicate between data centers under their jurisdiction. It doesn’t replace public cloud; it complements it.”
— David Carrero (Stackscale)
Practical patterns in private/hybrid (VMware/Proxmox):
- Active-active across two EU data centers for front ends, idempotent APIs, queues, and caches (with BGP/Anycast or simple GSLB).
- Synchronous/semi-synchronous replication for eligible data (latency < 5–10 ms between DCs).
- Immutable backups (3-2-1-1-0) with tested restores (monthly).
- Own DNS + CDN at the edge to absorb spikes and serve static content if origin wobbles.
- Observability outside the primary failure domain (logs/metrics/traces replicated).
- Orchestrator-down runbook: how do you operate without vCenter/Proxmox for hours?
Monday Morning Changes
- Map control-plane dependencies: what parts of your software must create/update resources to serve traffic? Propose degraded modes.
- Review DNS TTLs and internal resolvers: balance resilience with fix propagation.
- Tune load-balancer health checks: increase thresholds and add grace during mass deployments; avoid rules that remove half your fleet due to flapping.
- Intelligent throttling on retries: as the control plane returns, throttle to avoid self-DDoS.
- STS/IAM: stagger expirations and temporarily extend token lifetimes during incidents.
- Hot capacity: add buffer capacity (reservations, warm instances) to run without autoscaling for X hours.
- Practice regional failover: even if manual for now, rehearse it. If you use DynamoDB Global Tables, add client logic to fail over to replicas.
“The lesson isn’t ‘flee Virginia’; it’s don’t depend solely on Virginia—or any one region—for your coordination points. Spread the risk.”
— David Carrero (Stackscale)
Changes Announced by AWS (Useful for Your Planning)
- DynamoDB DNS automation disabled globally until the race is fixed and additional guardrails prevent bad plans.
- NLB: velocity control to limit how much capacity a single NLB can remove during AZ failover.
- EC2: new scale tests of the DWFM recovery flow and throttling improvements based on queue size.
Provider hardening is welcome—but your system resilience still comes down to your architecture and runbooks.
Conclusion
This wasn’t a mystical storm; it was a race bug in a critical, automated system (DynamoDB’s DNS) that left the endpoint without IPs and jammed self-healing—dragging the control plane with it. The SRE playbook (stop automation, restore manually, throttle, selective restarts) worked, but it took time. The real question for sysadmins isn’t if it will happen again; it’s when—and how it will find you: with hot capacity, controlled degradation, and rehearsed failover, or without any of that. In 2025, the sensible stance blends public cloud with a well-designed European private cloud, because diversity reduces risk.
FAQs
How do I design a realistic “degraded mode” if DynamoDB/IAM/STS is my dependency?
Define functional cut-offs: cached reads, read-only during spikes, temporary local queues, and feature flags to disable non-critical modules. Add backoff/jitter and per-service limits to avoid collapse when the control plane returns.
What DNS TTL do you recommend for managed services?
Avoid extremes: moderate TTLs (minutes) in internal resolvers buffer brief outages and let a provider fix propagate quickly. Pair with retries and circuit breakers on the client side.
If I can’t afford multi-region in public cloud, what do I gain with a European private cloud?
Control over topology, latency, and jurisdiction; active-active replication across two EU DCs for eligible workloads; and runbooks under your control. A hybrid setup gives you room when a third party’s control plane degrades.
Where should I start measuring improvement?
Define RTO/RPO, regional failover time, average TTFB post-incident, and “time to first content served” with origin down (CDN + cache). Track how many hours you can operate without the orchestrator or STS.