
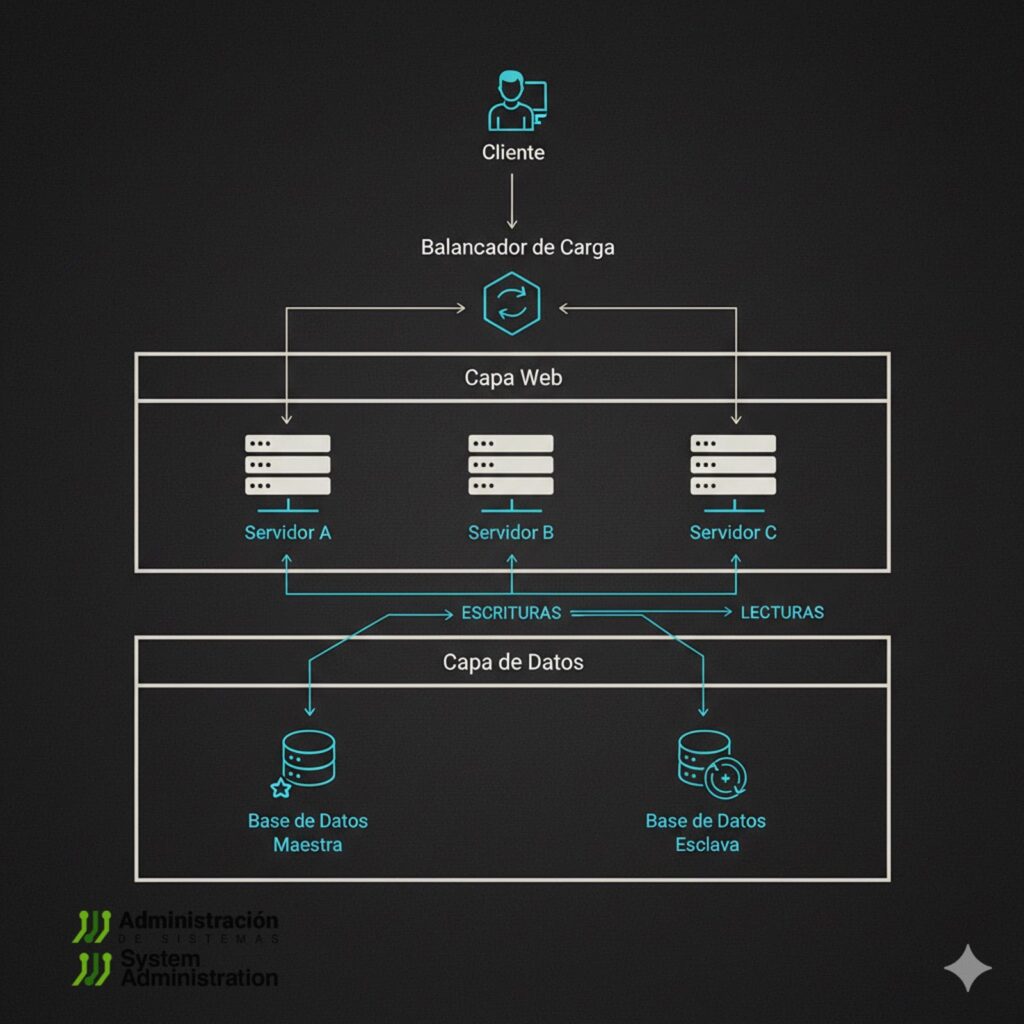
Your app takes off, CPU pins at 100%, memory burns, and one host is no longer enough. This is where every sysadmin turns into a systems architect: find the bottleneck, relieve it, repeat. The classic next step looks like the diagram above: a load balancer in front of multiple app servers (web tier), and a database with read replicas (data tier). Here’s how to get there without setting production on fire.
1) Two Ways to Grow
| Strategy | What it is | Pros | Cons |
|---|---|---|---|
| Vertical scaling | Add more CPU/RAM/IO to the same host | Operationally simple; no topology change | Finite ceiling, costly hardware, bigger blast radius |
| Horizontal scaling | Add more servers | Resilience, elasticity, better unit economics | Complexity: balancing, state, consistency, networking |
Rule of thumb: start vertical as long as the ROI is obvious. When your p95 latency plus sustained CPU/RAM show a physical ceiling, switch to horizontal.
2) The Load Balancer: Who Gets Each Request?
A Load Balancer (LB) answers “which server should handle this request?”
- L4 (TCP/UDP): fast, content-agnostic (IPVS/LVS, HAProxy TCP, cloud NLB).
- L7 (HTTP/HTTPS/gRPC): understands headers/paths, can do TLS termination, path/host routing, WAF (Nginx, HAProxy HTTP, Envoy, Traefik).
Common algorithms
- Round-robin (simple, good default).
- Least-connections (good when sessions vary).
- Weighted (mix different instance sizes).
- Consistent-hash (sticky by key; partition caches).
Health & outlier detection
- Active health checks (HTTP 200/3xx, TCP, gRPC).
- Circuit breaking/outlier ejection to evict flapping instances.
- Timeouts & bounded retries with backoff to avoid retry storms.
Sessions: sticky or stateless?
- Aim for stateless apps (session in Redis or signed JWT/cookies).
- If not yet possible, use stickiness (LB cookie or IP-hash). Know this reduces true balancing and complicates failover.
Minimal HAProxy (L7) example
frontend fe_https
bind :443 ssl crt /etc/haproxy/certs/site.pem
mode http
option httplog
default_backend be_app
backend be_app
mode http
balance leastconn
option httpchk GET /health
http-check expect status 200
server app1 10.0.1.11:8080 check
server app2 10.0.1.12:8080 check
server app3 10.0.1.13:8080 check
LB high availability
- Active/standby with VRRP/Keepalived (floating VIP) or anycast; in cloud, use managed ELB/ALB/NLB across AZs.
- Practice failovers: VIP takeover, connection drain, state handling.
3) The Bottleneck Moves: Your Database
Balancing the web tier multiplies concurrent DB clients. If every instance hits one database, the bottleneck slides to the DB. Before throwing hardware, squeeze three knobs:
- Connection pooling & proxies
- Postgres: pgBouncer (
transactionmode for chatty apps). - MySQL/MariaDB: ProxySQL.
- Too many connections hurt throughput—tune limits.
- Postgres: pgBouncer (
- Indexes & queries
- EXPLAIN/ANALYZE, composite indexes, avoid N+1.
- Watch locks, checkpoints, and vacuum (PG).
- Caching (next section).
When you still need more, add replication:
Primary + Read Replicas
- Primary handles writes;
- Replicas serve reads.
Sync model
- Asynchronous (typical): low latency, potential replication lag → eventual consistency.
- Synchronous: near-zero RPO, higher latency and stall risk.
Dealing with lag (read-your-writes)
- Route post-write reads for that user to primary for a short window.
- LSN/GTID-based reads: app carries last seen LSN/GTID; a proxy only uses replicas that have caught up (PG:
pg_last_wal_replay_lsn()). - Clear read/write routing in the pool; block non-safe queries on replicas.
Primary failover
- Orchestrate with Patroni, repmgr (PG) or orchestrator (MySQL).
- Decide RTO/RPO; prevent split-brain.
4) Cache: Your Best Defense Against Saturation
Where to cache
- CDN/edge for static and cacheable API responses.
- Reverse proxy (Nginx/Envoy) for page or fragment caching.
- App-level cache with Redis/Memcached for objects and query results.
Patterns
- Cache-aside (lazy-load): app checks cache, falls back to DB, then populates cache. Most flexible.
- Write-through: write to DB and cache—better consistency, slower writes.
- Write-behind: write to cache, persist later—faster writes, higher risk.
TTL & invalidation
- Use sensible TTLs; for strict consistency, explicitly invalidate (pub/sub, tags).
- Choose eviction (LRU/LFU) based on access pattern; watch for hot keys (consider sharding).
Dogpile/stampede protection
- Prevent a thundering herd when a hot key expires: locking (e.g.,
SETNX+ expiry) or request coalescing at the proxy. - Early refresh before TTL hits zero.
Cache-aside pseudo-code
def get_user(uid):
key = f"user:{uid}"
blob = redis.get(key)
if blob:
return deserialize(blob)
row = db.query("SELECT * FROM users WHERE id=%s", uid)
if row:
redis.setex(key, 300, serialize(row)) # 5-minute TTL
return row
Code language: PHP (php)5) When Replicas Aren’t Enough: Sharding & Partitioning
If the DB (or a single table) explodes in size/IO, consider partitioning:
- Sharding by tenant/user (hash or range): each shard is a smaller DB with its own primary/replicas.
- Native partitioning by date/range (PG native, MySQL has limits).
- CQRS: separate read and write models.
- Queues/events (Kafka/RabbitMQ/SQS) for heavy asynchronous work; ensure idempotency (Outbox pattern).
Caveat: sharding complicates joins, transactions, and multi-key ops. Don’t go there until you’ve exhausted replicas + cache + indexes.
6) Resilience Patterns: Timeouts, Retries, Backoff, Breakers
- Timeouts everywhere (client, LB, app, DB, cache). Without timeouts, failures become stuck threads.
- Retries with exponential backoff + jitter; never retry non-idempotent operations (or use idempotency keys).
- Circuit breakers: open the circuit after repeated failures to protect downstream systems.
- Rate limiting and WAF at L7.
- Queues to absorb spikes (buffering).
7) Observability & Capacity: No Metrics, No Scaling
Define SLOs (e.g., p95 < 300 ms, error rate < 1%). Instrument:
- LB: RPS, backend errors, outlier ejections, latency.
- App: p50/p95/p99 per endpoint, thread pool saturation.
- DB: QPS, locks, slow queries, replication lag, active connections.
- Cache: hit ratio, memory, evictions, hot keys.
- Infra: CPU, IOPS, network, throttling.
Use distributed tracing (OTel/Jaeger/Tempo) across LB → app → DB/cache. Build dashboards that span layers; alert on trends, not only static thresholds.
8) Safe Deploys: Blue/Green and Canary
- Blue/Green: two identical stacks; switch traffic via LB, instant rollback.
- Canary: ship to 5% → 25% → 50% while watching SLOs and error budgets.
- Auto-scaling: policies on CPU/RPS/latency; handle short spikes with warm-ups.
9) Security in the Architecture
- TLS termination at LB, consider mTLS inside if your threat model demands it.
- Secret management (no plain env), rotation.
- Least privilege for DB/cache; segmented security groups.
- Backups with tested RPO/RTO; DR across AZ/region.
10) Evolution Checklist
- Vertical scale; fix hot queries/code.
- LB + 2–3 app nodes; health checks, least-conn.
- Connection pooling (pgBouncer/ProxySQL).
- Redis cache (cache-aside) + CDN for static.
- Read replicas; clear read/write routing; read-your-writes.
- Full observability, SLOs, canary deploys.
- LB HA (VRRP/ELB) + auto-scaling.
- If needed: partitioning/sharding; queues for async.
- DR multi-AZ/region, regular failover drills.
A Final Field Note
Horizontal scale buys headroom, but every step introduces trade-offs: stickiness vs. stateless, latency vs. consistency, cost vs. simplicity. The real job is choosing deliberately what to sacrifice and measuring whether the choice pays off. Designing systems is exactly that: find today’s bottleneck and put in place what you need so tomorrow your app can keep growing—without your on-call going up in flames.