
Over the past decade, artificial intelligence has been closely tied to the cloud. When a user chats with ChatGPT, Gemini, or Claude, their request travels to a data center where thousands of GPUs work in parallel to generate a response. Without these silicon giants, AI would not be possible.
However, things are changing: mobile hardware is reaching a point where it can run optimized versions of language models. This shift is giving rise to a new generation of applications such as PocketPal AI, an app available for iOS and Android that allows users to download and run AI models directly on their phones—without an Internet connection.
This development not only has major implications for privacy but also signals the beginning of a technological decentralization: from the cloud to the pocket.
How can an LLM run on a smartphone?
The secret lies in optimization techniques that shrink the size and complexity of language models to make them compatible with limited hardware. Some of the most important are:
- Quantization: converts model parameters (typically in 16 or 32 bits) into more compact formats such as 8, 4, or even 2 bits. This dramatically reduces model size and required RAM. Formats like GGUF are now the standard for running LLMs on modest devices.
- Pruning: eliminates less relevant neural connections, reducing computational load with minimal accuracy loss.
- Inference optimization: libraries such as llama.cpp, GGML, or MLC LLM are designed to take advantage of mobile accelerators (GPU, NPU, DSP) to maximize tokens per second.
Thanks to these techniques, models that originally weigh tens of gigabytes (like LLaMA-3 in its full 70B parameter version) can be compressed into versions of just 2–4 GB, light enough for a modern smartphone.
Hardware requirements
Running AI locally is no trivial task. These are the key factors:
- Available RAM: a 7B parameter model quantized to 4 bits may require 3–5 GB of RAM. Phones with at least 8 GB are the practical minimum for PocketPal AI.
- CPU/GPU/NPU: today’s mobile chips integrate AI accelerators. For example:
- Apple A17 Pro and M1/M2/M3: NPUs reaching up to 35 TOPS.
- Snapdragon 8 Gen 3 / X Elite: Hexagon NPU optimized for LLMs.
- AMD Ryzen AI 300: designed for Copilot+ PCs with native local model support.
- Storage: each model takes up 1–4 GB, so having multiple models quickly fills device memory.
- Battery consumption: local inference drains power fast. A 30-minute session can reduce battery life by up to 20% on some phones.
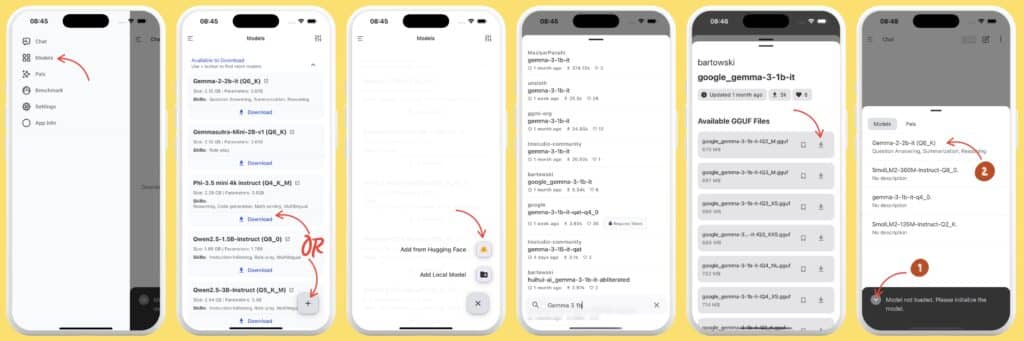
PocketPal AI in action: installation and usage
The app offers an experience tailored for both casual users and AI enthusiasts:
- Model selection: users can choose from popular options such as Gemma (Google), Llama (Meta), Phi (Microsoft), or Qwen (Alibaba). It also supports integration with Hugging Face for downloading hundreds of additional models.
- Download and load: the chosen model is downloaded in quantized format and loaded into memory on demand. The app automatically frees RAM after sessions.
- Interaction: similar to a standard chatbot, but with real-time metrics: tokens per second, CPU/GPU usage, RAM consumption.
- Customization: via the Pals feature, users can create different AI “personalities” with communication styles adapted to their needs.
Performance: what to expect on mobile
Performance depends on the device and the model. These are reference values measured on 2024–2025 high-end phones:
- LLaMA 3 8B quantized to 4 bits: 15–20 tokens/sec on an iPhone 15 Pro.
- Phi-3-mini 3.8B: 25–30 tokens/sec on Snapdragon 8 Gen 3.
- Mistral 7B: 12–18 tokens/sec on a Pixel with Tensor G3.
In practice, this means 1–3 seconds per short sentence, fast enough for conversational use.
Advantages over the cloud
- Full privacy: no conversation leaves the device.
- Offline availability: ideal for travel, remote areas, or sensitive environments (military, healthcare).
- Zero server costs: no need to pay for cloud compute usage.
Limitations
- Reduced models: SLMs (small language models) can’t match GPT-4 or Claude Sonnet in complex tasks.
- Battery drain: prolonged inference quickly depletes the battery.
- Context length: most models run with 4k–8k token windows, far smaller than the 128k+ of cloud LLMs.
PocketPal AI and the decentralization of AI
The most important aspect of PocketPal AI isn’t just the app itself, but what it represents: the start of a decentralization of computing power.
In the 2000s, computing migrated from personal computers to the cloud. Now, the journey may be reversing: back to the edge, where intelligence runs close to the user.
Apple, Microsoft, Google, and Qualcomm are already moving in this direction, integrating ever more powerful NPUs into their devices. PocketPal AI proves that the trend is feasible today, not just in theory.
Conclusion
PocketPal AI introduces a new paradigm: artificial intelligence that runs without the cloud, without an Internet connection, and under the user’s direct control. While still limited compared to cloud giants, it offers an alternative balancing privacy, autonomy, and accessibility.
In a world where each ChatGPT query consumes the same energy as a small city, solutions like PocketPal AI point toward a more sustainable and user-centric path.
The future of AI may not only lie in massive server farms—but also right in your pocket.
Downloads avalaible in Android, iPhone andl código fuente en GitHub.