
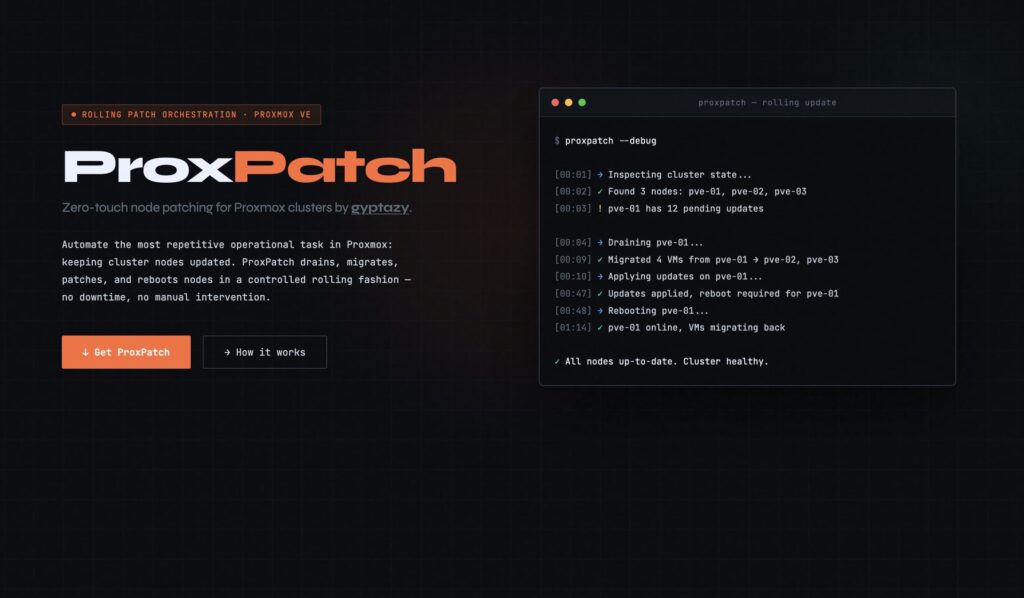
Updating a Proxmox VE cluster may seem like a routine task until it has to be done node by node, with virtual machines running in production, tight maintenance windows and the risk of leaving a host half-rebooted. ProxPatch was created precisely to automate that repetitive work: drain a node, migrate the virtual machines, apply patches, reboot if necessary and repeat the process with the next server in the cluster.
The tool, developed by gyptazy, is presented as a lightweight rolling update orchestrator for Proxmox VE. Its goal is not to replace a high availability solution or become a full lifecycle management platform. It does one specific job: keeping the nodes of a Proxmox cluster updated with the lowest possible impact on running workloads.
This fits with an increasingly visible reality in virtualized environments: security does not depend only on backups or proper segmentation. It also depends on applying patches on time. In Proxmox VE-based platforms, where many companies and providers are migrating from VMware or deploying private clouds on bare-metal infrastructure, automating node updates can reduce human error and improve operational discipline.
A simple task to explain, but a delicate one to execute
ProxPatch follows a workflow familiar to any systems administrator. First, it inspects the cluster state using native Proxmox tools. Then it identifies which nodes have pending updates, moves virtual machines away from the host that is going to be patched, applies updates over SSH, checks whether a reboot is required and waits for the node to come back online before moving on to the next one.
Doing this process manually requires constant attention. The administrator has to check quorum, review cluster health, make sure there is enough capacity on other nodes, migrate workloads, launch updates, decide whether a reboot is required and verify that everything has returned to normal. In a small lab, this may be manageable. In a cluster with several dozen nodes, it becomes an operation that is easy to get wrong.
ProxPatch tries to make that process predictable and auditable. The tool logs every step with timestamps and avoids continuing if it detects that the cluster is degraded or that quorum may be at risk. Its philosophy prioritizes safety over speed: the goal is not to update as quickly as possible, but to do it without breaking the availability of the environment.
The tool uses components already present in many Proxmox deployments, such as pvesh, qm and SSH. According to its documentation, it does not require external databases or orchestration frameworks. However, the idea of “zero dependencies” should be understood with some nuance: the GitHub repository indicates that it requires jq on the machine running it to process JSON, as well as SSH access to the cluster nodes.
Designed for clusters with live migration
ProxPatch makes sense when the cluster can move workloads from one node to another without stopping them. That is why its documentation recommends at least three nodes, stable quorum and shared storage, such as Ceph or NFS, to allow live migration. Key-based, passwordless SSH access between the node running ProxPatch and the rest of the servers is also recommended.
This point matters because the tool does not work miracles. If a cluster does not have enough spare capacity to absorb the virtual machines from one node during maintenance, if storage does not support live migration or if the network is poorly designed, automation will not solve those underlying issues. ProxPatch can organize the process, but the cluster architecture must be ready for it.
Installation is done through gyptazy’s Debian repository. The documentation states compatibility with Debian bookworm and trixie, as well as Proxmox VE 8.x and 9.x environments. The package must be installed and executed on a single node in the cluster, which is an important warning: the proxpatch service should not be enabled on several nodes at the same time, because the tool is designed to act as a single orchestrator.
Its configuration is intended to be minimal. In many cases it can work without an additional configuration file, although settings can be adjusted through /etc/proxpatch/config.yaml. Basic usage consists of enabling and starting the systemd service, after which the rolling update process begins.
Relationship with ProxLB and a very specific philosophy
ProxPatch started as an idea linked to ProxLB, another gyptazy project focused on load balancing in Proxmox clusters. ProxLB acts as a kind of resource scheduler to distribute virtual machines across nodes, covering a gap some administrators miss when comparing Proxmox with more traditional virtualization platforms.
According to the author, the lack of certain Proxmox API endpoints to manage rolling patching and node reboots made it more reasonable to create a separate tool instead of adding workarounds into ProxLB. The result is a smaller, more focused and easier-to-audit project. ProxPatch can work alongside ProxLB, but does not depend on it.
That minimalist approach has both advantages and limits. The advantage is that administrators can understand what the tool does without having to deal with a heavy platform. The limit is that ProxPatch is not intended to manage the full lifecycle of the cluster, nor does it replace practices such as backups, monitoring, pre-production testing, configuration management, change documentation or rollback plans.
It is also worth noting that the GitHub repository itself includes a clear warning: the project is at an early stage and should be considered experimental. The author recommends not using it in production without thorough testing in lab or staging environments. That is a reasonable warning for any tool that automates sensitive operations such as migrations, updates and node reboots.
The appearance of ProxPatch reflects a broader symptom of the Proxmox ecosystem. As more organizations adopt it for enterprise virtualization, private cloud, advanced lab environments or as an alternative to VMware, the need grows for operational tools that reduce manual work. Proxmox VE provides a solid foundation, but many advanced automation functions still depend on the community, scripts, APIs or external projects.
In that context, ProxPatch may fill a useful gap. It does not turn Proxmox into a closed platform or try to hide how it works. On the contrary, it focuses on visible automation, based on native tools and a very specific function. For administrators who already perform rolling updates manually, it can become a way to standardize the procedure and reduce variations between maintenance operations.
Its real value will depend on its maturity, how the project evolves and the trust it gains within the community. In critical environments, any tool of this kind must be tested against real scenarios: insufficient spare capacity, failed migrations, hosts that do not return after reboot, kernel updates, workloads with special dependencies and clusters using Ceph. Automation is only reliable when it also knows when to stop.
ProxPatch does not remove responsibility from the administrator. But it does point in a necessary direction: if Proxmox VE is to keep gaining ground in professional environments, repetitive and delicate tasks must become more predictable, auditable and easy to repeat. Patching nodes without taking virtual machines offline is one of them.
Frequently asked questions
What is ProxPatch?
ProxPatch is an open source tool for automating rolling updates in Proxmox VE clusters. It migrates virtual machines, applies patches and reboots nodes when required.
Does ProxPatch completely avoid downtime?
Its goal is to keep workloads running through live migration, but this depends on a properly designed cluster with quorum, available capacity and shared storage.
Can ProxPatch be used in production?
The project is presented as experimental, and its own repository recommends testing it first in a lab or staging environment. It should be carefully evaluated before production use.
What are ProxPatch’s requirements?
It requires a Proxmox VE cluster, preferably with at least three nodes, stable quorum, shared storage for live migration, SSH access to the nodes and jq for JSON processing.