
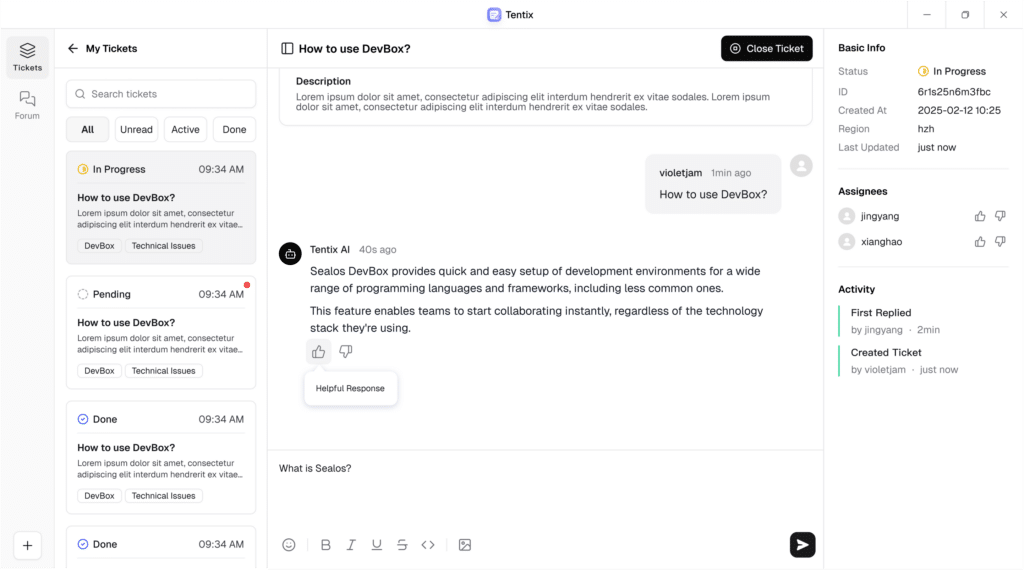
Customer support teams are living through a familiar contradiction: there are more dashboards than ever to track response times and SLAs, yet many organizations still get stuck in the same loop—repeated issues, scattered documentation, tribal knowledge trapped in chat threads, and the constant “Where did we solve this last time?”
That’s the pain point TenTix is targeting. Built and published as an open-source project by labring, Tentix positions itself as an AI-native customer service platform designed to speed up resolution by combining agent workflows with a structured knowledge base built from real support artifacts—tickets, marked “starred” conversations, and general documentation.
The pitch is bold—“10× efficiency”—but the architecture it outlines lines up with what’s increasingly becoming the modern pattern for support at scale: turn support history into a searchable semantic knowledge layer (RAG), then let an agent orchestrate retrieval and response in a controlled way.
A support “brain” built from what teams already have
At the core of Tentix is a knowledge base builder that can ingest multiple types of information and normalize them into a single retrieval system:
- Starred conversations (the “gold” threads teams already trust)
- Historical tickets (especially solved, high-quality ones)
- General documentation (internal guides, FAQs, playbooks)
The point isn’t to create another document repository. Tentix is designed to transform these sources into retrievable knowledge using embeddings and semantic search.
A pragmatic decision here is the vector backend: PostgreSQL + pgvector. For many teams, that’s a strong “production-friendly” choice because it keeps the architecture simpler than introducing a separate vector database right away—especially if the organization already operates Postgres reliably.
Tentix also describes knowledge prioritization, assigning weights depending on source type (e.g., starred conversations higher than generic docs). That’s a real-world support insight: what worked in an actual ticket or a verified internal thread is often more reliable than a broad, out-of-date wiki page.
Agent workflows with guardrails: LangGraph at the center
Tentix describes its AI response flow using LangGraph, organizing the agent’s behavior into a structured workflow:
- Analyze the ticket/user message
- Refine the query
- Retrieve relevant knowledge from the vector KB
- Generate a response
In support environments, this matters because the biggest risk with “AI answers” isn’t just hallucination—it’s unpredictability. A workflow-driven approach can make the system more debuggable and auditable: the team can understand how the agent searched, what it retrieved, and why it responded the way it did.
The project also mentions support for MCP (Model Context Protocol) extensions, signaling an intent to keep the platform extensible as agent ecosystems standardize the way models connect to tools and data sources.
Built for real deployment: container-first setup and practical dependencies
Tentix reads like it expects to be deployed by people who actually run systems. It defines a clear stack and requirements:
- Bun (≥ 1.2.16) as runtime/tooling
- PostgreSQL with pgvector
- MinIO (or any S3-compatible object storage) for media and attachments
- OpenAI/FastGPT credentials for AI features (summarization, embeddings, chat)
The deployment workflow is familiar to modern open-source infra:
- Build a Docker image
- Run database migrations (reading from
.env.local) - Configure environment variables (DB URL, encryption key, storage credentials, model settings)
- Start the container (default port 3000, health check endpoint /health)
There’s also a small but important security signal: Tentix requires an ENCRYPTION_KEY (Base64), and separates infrastructure secrets (database, storage) from AI parameters (model choices, token limits, temperature, etc.). In other words, it’s designed to operate like a production service, not a weekend demo.
Beyond a chatbot: notifications, admin controls, and the reality of support ops
Tentix isn’t presented as “just a bot.” It includes the surrounding systems support teams depend on:
- A customer service chat system
- Multi-channel notifications, with explicit support for Feishu and modular integrations for other channels
- A unified auth design with pluggable third-party integrations
- Admin configuration for the agent model (temperature, TopP, max tokens, etc.)
- Optional vector backends beyond pgvector (e.g., an external vector service)
The roadmap reinforces that Tentix is aiming at the operational layer, not only response generation. Planned features include:
- Knowledge base indexing schedules for historical tickets and general docs
- KB hit testing and visualization (quality checks without opening real tickets)
- Prompt customization and workflow orchestration (A/B testing agent behavior)
- Analytics: ticket distribution, KB hit rate, volume trends, feedback trends, handoff metrics
- Agent dashboards with personal metrics and index tooling
Those are the capabilities that decide whether a support platform becomes a core system—or another tool that never escapes pilot mode.
Why this approach is gaining traction in 2025
Tentix is also a sign of where support automation is heading. The industry is moving away from the assumption that “bigger models automatically mean better support.” In practice, support quality often depends more on the pipeline than on the model:
- How clean and up-to-date the knowledge is
- How retrieval is prioritized
- How the agent is constrained and evaluated
- How human handoffs are handled
- How the system is monitored, audited, and improved over time
That’s why RAG-first systems and workflow-driven agents are resonating: they can be measured, tuned, and integrated into the existing support process.
Tentix’s challenge, like every platform in this space, will be execution: it has to prove it can reduce workload and resolution time without increasing operational overhead. But architecturally, it’s aligned with what teams increasingly want—a support brain built from their own history, served through a controlled agent workflow.
FAQs
What is Tentix, and who is it for?
Tentix is an open-source, AI-native customer support platform designed for teams managing tickets and recurring issues—SaaS support, IT help desks, technical support organizations, and any company with a large support knowledge footprint.
How does PostgreSQL + pgvector help in an AI support platform?
It enables semantic search over embedded knowledge (tickets, docs, conversations) inside a standard Postgres database, simplifying infrastructure while still supporting vector retrieval for RAG workflows.
Why use LangGraph for customer support agents?
LangGraph helps define explicit agent steps (analyze → refine → retrieve → answer), making responses more predictable and easier to debug than free-form prompting alone—important when answers impact customers.
What do you need to deploy Tentix with Docker?
Bun, Postgres with pgvector, S3-compatible object storage like MinIO, and (optionally) AI provider credentials for embeddings/summarization/chat. You’ll also configure environment variables like DATABASE_URL and an encryption key.
If you want, I can also produce a shorter “tech news” version (400–500 words) or a more product-led version for a DevOps/SRE audience.