
Modern OCR has improved significantly in accuracy, but it still faces an awkward problem when dealing with long documents. Many systems split the PDF into pages, process each image separately, reconstruct the text, try to preserve tables, headings, notes, columns and reading order, and then pass that result to a vector database or a RAG system. It works, but every jump between pages introduces opportunities for error.
Baidu wants to address that bottleneck with Unlimited-OCR, a new open model for document recognition and parsing designed for what its authors call “one-shot long-horizon parsing”: processing multi-page documents in a single pass, reducing the need to split, stitch and manually correct the output. The project has been published on GitHub and Hugging Face under the MIT license, with model weights and inference code available for Transformers and SGLang.
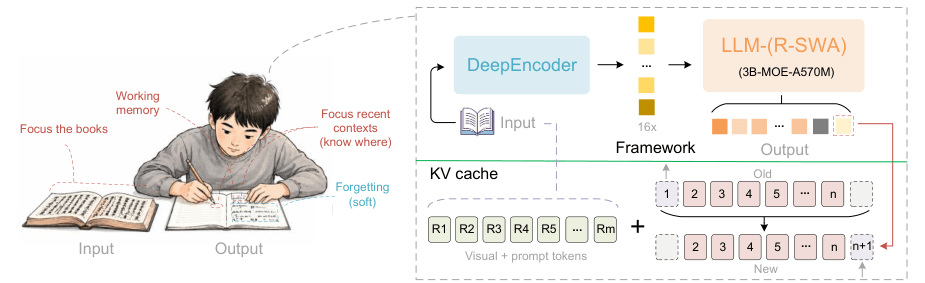
The underlying idea is easy to explain, even if technically demanding: keep the document visible to the model, but prevent generation memory from growing uncontrollably as more text is produced. In a conventional OCR system based on language models, the longer the output, the larger the KV cache becomes and the more memory the system consumes. Unlimited-OCR introduces Reference Sliding Window Attention, or R-SWA, to keep memory constant during decoding.
The problem with splitting PDFs page by page
Most enterprise document workflows still follow a familiar recipe. First, each PDF page is converted into an image. Then OCR or parsing is run page by page. The full document is reconstructed afterwards, and finally chunks are created for semantic search, RAG or analysis with language models.
That process has several weak points. If a table continues across pages, if a footnote depends on a previous section, if a document has two columns or if a chart is explained on the following page, the system can lose context. In contracts, financial reports, administrative files, technical manuals or scientific documentation, that loss of continuity matters.
Unlimited-OCR does not remove all those challenges, but it tries to change the unit of work. Instead of treating each page as an isolated piece, it allows the model to process multiple pages as part of the same parsing task. This can reduce reconstruction errors and improve the coherence of extracted text when the document has a complex structure.
The repository itself still performs an initial PDF-to-image conversion using PyMuPDF. In other words, this is not a magic reader that opens any PDF without intermediate processing. The important difference is that those page images are passed together to the model for multi-page inference, instead of forcing an independent cycle for each page.
| Approach | How it works | Main risk |
|---|---|---|
| Classic page-based OCR | Processes each page separately | Loses context between pages |
| OCR + RAG pipeline | Extracts, reconstructs, chunks and indexes | Accumulated errors when stitching the document |
| Standard VLM with long output | Keeps context, but memory grows with the output | Cost and latency increase with long documents |
| Unlimited-OCR | Keeps visual references and uses a sliding window of generated text | Still limited by context length and input image quality |
What R-SWA brings
The main technical contribution of Unlimited-OCR is Reference Sliding Window Attention. The mechanism separates the model’s attention into two parts. On one side, it preserves access to reference tokens, which in this case are the document’s visual tokens. On the other, it keeps only a recent window of generated tokens, instead of indefinitely carrying the entire previous output.
This allows the KV cache to remain constant during decoding. The model does not need to “remember” every word it has already emitted with the same growing cost as full attention. For copying, transcription or parsing tasks, that limitation is reasonable: the model needs to know where it is, maintain continuity and avoid repetition, but it does not always need to attend to every generated token from the beginning.
The practical consequence is that performance degrades less as output length increases. In the technical report, Baidu compares Unlimited-OCR with DeepSeek-OCR and shows that, in long scenarios, the new mechanism maintains generation speed more effectively. In theoretical long-output tests, the advantage increases as the number of tokens grows.
The model builds on DeepSeek-OCR as a reference and keeps its high-compression visual encoder. Its architecture is MoE-based, with 3 billion total parameters and 500 million active parameters, which helps contain inference cost. Baidu claims that Unlimited-OCR reaches 93.23% on OmniDocBench v1.5 and 93.92% on OmniDocBench v1.6, with improvements over the DeepSeek-OCR baseline in text editing, formulas, tables and reading order.
Why it matters for RAG and corporate archives
The most interesting impact is not just “faster OCR”. It is improving the quality of the text that feeds search systems, document classification, agents and RAG. If the document is poorly broken before entering the index, everything that happens afterwards inherits that error. A RAG system with clean chunks, correct reading order and continuity across pages has a much better chance of answering accurately.
This is especially important for companies with large document repositories: scanned contracts, regulatory reports, technical documentation, product manuals, case files, invoices, presentations, legal documents, historical archives or scientific PDFs. In many of those cases, the value is not only in recognising words, but in preserving structure.
OCR for a simple invoice or a scanned page is already fairly mature. The harder problem is different: long, dense documents with tables, formulas, headers, notes, columns, footers, charts and cross-references. That is where classic pipelines start accumulating patches.
For teams building document AI systems, Unlimited-OCR points to a cleaner architecture: less manual reconstruction, less stitching logic between pages, less dependence on external rules and more end-to-end parsing. This does not replace validation, nor does it remove the need to test results in critical domains, but it can reduce a heavy part of the preprocessing workload.
An open tool, but still a technical one
Unlimited-OCR is not designed for an end user who wants to drag a PDF into a simple interface and forget about it. It is a research and technical deployment tool. The repository includes examples for inference with Hugging Face Transformers on NVIDIA GPUs, with dependencies tested on Python 3.12.3 and CUDA 12.9. It also offers an SGLang route to serve the model through an OpenAI-compatible API.
Multi-page inference uses a base mode with images at 1,024 pixels. For PDFs, the example converts each page into a PNG at 300 dpi and then calls infer_multi. Options are also included for batch processing from an image directory or from a PDF.
This opens the door to internal workflow integration, but it requires technical judgement. Loading models with trust_remote_code=True, serving internal endpoints, processing sensitive documents or indexing outputs for RAG requires security controls, isolation, dependency review and quality testing. The MIT license makes experimentation and adoption easier, but it does not automatically turn the model into a finished enterprise solution.
| Aspect | Relevant detail |
| Developer | Baidu Inc. |
| Model | Unlimited-OCR |
| Type | End-to-end OCR and document parsing with vision-language modelling |
| Size | 3B-A0.5B |
| Main technique | Reference Sliding Window Attention |
| Inference context | 32K in published examples |
| PDF input | Prior conversion to images with PyMuPDF |
| Execution | Transformers and SGLang |
| License | MIT |
| Use cases | Long PDFs, RAG, corporate archives, technical documents |
It is not truly “unlimited”
The name can lead to an exaggerated reading. Unlimited-OCR does not allow any document of arbitrary length to be processed without limits. The authors themselves acknowledge that truly unlimited parsing cannot be achieved with a finite window such as 32K, because prefill length also grows as more pages are accumulated. Their short-term plan is to train models with longer contexts, such as 128K, to support more pages in the input.
There are also practical limits. In documents longer than 40 pages, the report maintains reasonable results, but notes that repeated errors often appear when small PDF text is hard to discern, especially because of the base-mode resolution used in multi-page scenarios. This recalls a basic OCR rule: if the input image does not contain enough visual information, the model cannot invent a reliable reading.
Even so, the proposal is relevant because it changes the direction of the problem. For years, it has been accepted that long-document processing had to be divided into many small operations. Unlimited-OCR suggests that, with a better-designed working memory, the model can maintain continuity for longer without generation cost exploding.
The lesson for companies is clear. The bottleneck in document AI is not only the model that answers questions, but the quality of the text it receives. If PDFs are fragmented poorly, if tables are lost or if reading order breaks, the final system fails even when using a strong LLM. Improving long-document OCR may look like an infrastructure upgrade, but it directly affects the accuracy of assistants, internal search engines and corporate agents.
Unlimited-OCR arrives at a time when enterprise AI is starting to look less at demos and more at real operations. Reading thousands of documents, preserving context and delivering structured text is not a flashy feature, but it is one of the foundations of any useful system. Baidu has put forward an open solution that will need to be tested outside the paper, with difficult documents and real workloads, but its approach targets one of RAG’s most persistent problems: before reasoning over knowledge, you have to extract it properly.
Frequently asked questions
What is Unlimited-OCR?
Unlimited-OCR is an open Baidu model for OCR and long-context document parsing. It is designed to process multi-page documents in a single task, reducing the need to reconstruct PDFs page by page.
How is it different from traditional OCR?
The key difference is its R-SWA mechanism, which keeps access to the document’s visual tokens while preserving only a sliding window of generated text. This prevents memory from growing indefinitely during long outputs.
Can it be used for RAG systems?
Yes. It can be useful as a preprocessing layer for RAG because it improves text extraction and continuity in long documents. A RAG index depends heavily on the quality of the initial parsing.
Is it really unlimited?
Not literally. The model is still limited by the available context, such as the 32K tokens used in the published examples, and by the visual quality of the pages. The name reflects the goal of reducing the growing cost of long generation, not the total absence of limits.