
Running local AI on a Mac has usually meant choosing between convenience and control. Developers could get a model running quickly, but once they tried to use that setup for real coding work, long contexts, multiple requests, or agent-style workflows, the limitations showed up fast. That is the gap oMLX is trying to close. The open-source project positions itself as an inference server built specifically for Apple Silicon, combining continuous batching, SSD-backed KV cache persistence, a native macOS menu bar app, and drop-in API compatibility with OpenAI- and Anthropic-style clients. In practical terms, it aims to make local LLM serving on a Mac feel less like a hobbyist experiment and more like a lightweight piece of infrastructure.
That matters because local AI is no longer just a privacy play. For developers and sysadmins, it is increasingly about workflow reliability, predictable costs, lower latency for repeated tasks, and keeping coding agents close to the codebase instead of routing every request through an external API. oMLX leans directly into that use case. Its official documentation explicitly frames the product around agentic coding workloads, where prompts change often, context gets invalidated repeatedly, and recomputing large prefixes becomes the real bottleneck.
Built for the part local AI usually gets wrong
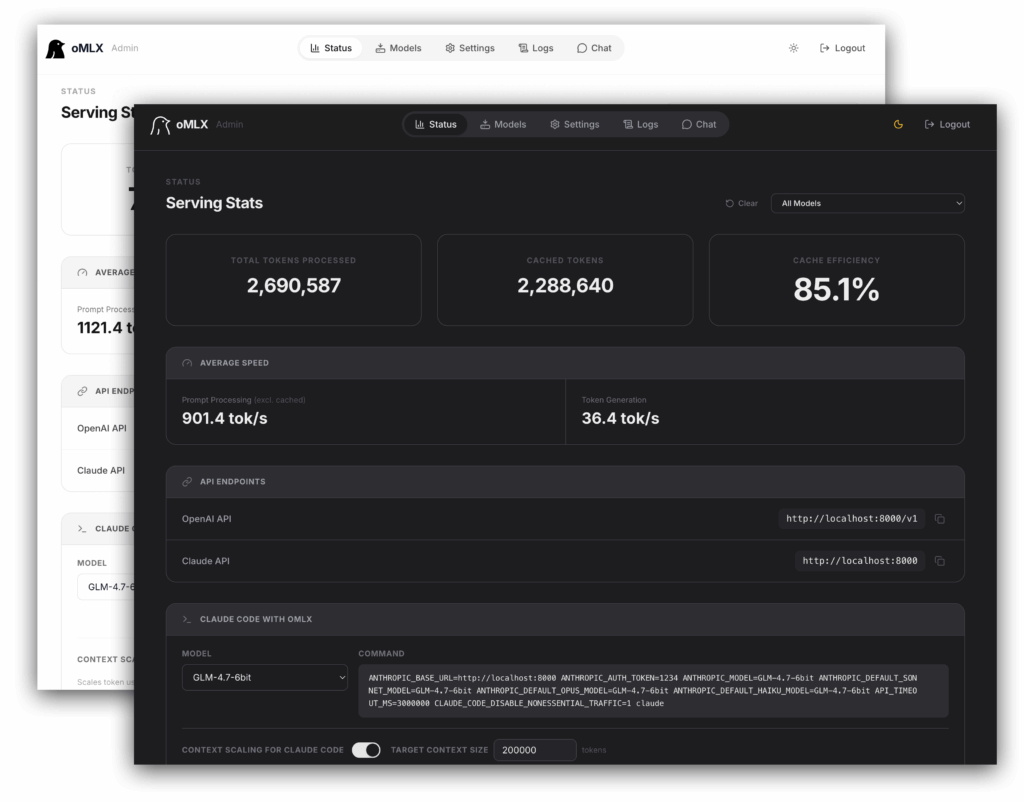
The most interesting part of oMLX is not that it serves models locally. Many projects already do that. The more important point is how it handles context reuse. According to the project’s documentation, oMLX uses a two-tier KV cache design: a hot tier in RAM and a cold tier on SSD. When memory fills up, cache blocks can be offloaded to disk in safetensors format and later restored if a request reuses a matching prefix. The idea is simple but important: in coding workflows, the expensive part is often not generating a short answer, but rebuilding a large context window over and over as prompts evolve. oMLX tries to avoid that waste by treating SSD as an extension of context persistence rather than starting from scratch every time.
The second pillar is continuous batching. The server uses mlx-lm’s batch generator to handle concurrent requests, which makes it better suited to real-world usage patterns where an editor plugin, a local coding agent, a dashboard, and a CLI may all be talking to the same backend. On its website, oMLX claims up to a 4.14x generation speedup at 8x concurrency, while the GitHub repository describes configurable limits for concurrent requests and process-level memory enforcement. Those numbers will depend heavily on the model, the machine, and the prompt mix, but the direction is clear: this is not meant to be a single-user chat toy. It is meant to behave more like a local service.
A local AI stack that looks more like a product
One reason local inference remains niche outside advanced users is that too many tools still feel like tools for people who enjoy wiring everything together by hand. oMLX takes a different approach. It ships as a native macOS app, installable via DMG, Homebrew, or source, and the app lives in the menu bar instead of forcing users into a terminal-first workflow. The project stresses that the macOS app is built with PyObjC rather than Electron, includes in-app auto-update, and can start, stop, and monitor the server directly from the menu bar. For sysadmins and power users, it can also run as a background service through brew services, with logs written both to the Homebrew log path and to a structured server log under ~/.omlx/logs/server.log.
That dual approach is probably one of its smartest design choices. Developers who want a fast “drag to Applications and go” experience get that. Users who treat local inference as a service can manage it with Homebrew, persistent settings, and log files. That makes oMLX more interesting for workstation setups, internal labs, small dev teams, and even support engineers or sysadmins who want a repeatable local AI service on managed Apple hardware without turning every machine into a snowflake.
Why developers should pay attention
For software developers, the biggest selling point is compatibility. oMLX exposes endpoints such as /v1/chat/completions, /v1/completions, /v1/messages, /v1/embeddings, /v1/rerank, and /v1/models, which means tools already built around OpenAI or Anthropic formats can often be redirected to a local endpoint with minimal friction. The admin dashboard also includes one-click integrations for tools such as OpenClaw, OpenCode, and Codex, which reinforces the project’s focus on coding workflows rather than generic local chat.
It also supports more than plain text LLMs. The repository lists support for vision-language models, OCR models, embedding models, and rerankers, all managed within the same server. That makes oMLX more relevant for retrieval pipelines, local document tooling, multimodal workflows, and experimental agent stacks that need more than one model type at once. In the latest release candidate published on April 14, 2026, the project also added three OpenAI-compatible audio endpoints — /v1/audio/transcriptions, /v1/audio/speech, and /v1/audio/process — powered by mlx-audio, which pushes the platform even further into general-purpose local inference territory.
Why sysadmins should care too
From a sysadmin perspective, oMLX is interesting because it starts to look like a manageable local service rather than a fragile developer side project. It has persistent configuration, service management through Homebrew, API key authentication, configurable memory ceilings, structured logging, and model lifecycle controls such as LRU eviction, model pinning, per-model TTL, and manual load or unload from the admin panel. Those features are not glamorous, but they are what separate “it runs on my laptop” from something that can be standardized across machines.
The system requirements are also explicit: macOS 15.0 or later, Python 3.10+, and Apple Silicon. That narrows the deployment surface in a useful way. Teams standardizing on recent Mac hardware — especially M-series workstations with larger unified memory pools — can evaluate oMLX without guessing whether the platform is an afterthought. The project is also licensed under Apache 2.0, which makes it easier to assess for enterprise or internal tooling use than projects with fuzzier licensing terms.
A sign that local AI on Mac is maturing
oMLX does not remove the hardware limits of Apple Silicon, and it does not turn every MacBook into a substitute for a GPU server. Model size, context length, available memory, and SSD performance still matter. But that is not really the point. The real significance of oMLX is that it shows local inference on macOS is moving beyond novelty. It is starting to adopt the characteristics of actual infrastructure: persistent cache, background services, admin dashboards, model lifecycle controls, API compatibility, and an opinionated UX for real workflows.
That shift matters for the AI tooling landscape. As more developers and operators look for ways to keep some AI workflows local, reduce recurring API costs, or build agent systems that can survive without constant dependence on remote providers, the demand for robust on-device inference will keep growing. oMLX may not be the final answer for every Mac-based AI stack, but it is one of the clearest signs yet that local AI on Apple Silicon is starting to grow up.