
Anthropic has not published the internal architecture of Claude Mythos Preview. What it has confirmed is that this is its most powerful model to date, that access remains limited to a research preview, and that its initial deployment is closely tied to Project Glasswing, the program through which the company aims to strengthen the security of critical software. In other words, Mythos exists, it is already being used in highly controlled real-world settings, but its design remains opaque.
That is where OpenMythos comes in. Kye Gomez’s repository does not claim to have leaked or reproduced Anthropic’s model. Instead, it proposes a “theoretical reconstruction” built on public research and one specific hypothesis: that Mythos may belong to the family of Recurrent-Depth Transformers, also known as looped transformers. The project is implemented in PyTorch, released as open source, and explicitly presented as an independent effort, with no affiliation to Anthropic.
For a programming and systems administration audience, the interesting part is not the speculative branding around the name, but what OpenMythos makes possible to study: an architecture in which reasoning depth does not depend only on stacking more layers, but on reusing the same block multiple times within a single inference pass. That shifts the debate away from “how many parameters the model stores” toward “how much effective compute it consumes per request and how that compute scales at runtime.”
What OpenMythos actually implements
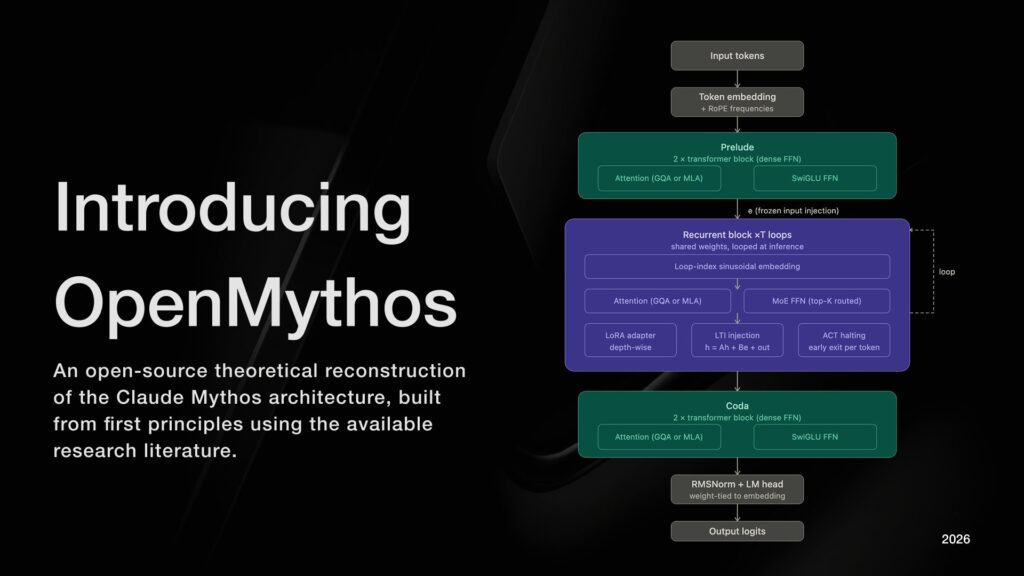
According to its README, OpenMythos structures the model in three phases: a Prelude with standard transformer layers, a recurrent block that runs multiple times, and a final Coda. The core lies in that shared recurrent block, where the hidden state is updated iteratively with the rule ht+1=A⋅ht+B⋅e+Transformer(ht,e). The repository allows switching between MLA and GQA for attention, uses a sparse MoE feed-forward with routed experts and shared experts, and adds depth-wise LoRA adapters to slightly differentiate behavior at each iteration.
That means that, in practical terms, the project combines several recent architectural ideas: weight reuse, implicit reasoning in latent space, MoE to expand capacity without activating the full model at once, and depth-wise LoRA to prevent every loop iteration from doing exactly the same thing. OpenMythos also exposes preconfigured variants ranging from 1B to 1T theoretical parameters, with settings that scale dimension, number of experts, context window, and maximum loop iterations.
From an operational perspective, this introduces an important difference from a standard dense transformer. In a fixed model, computational depth is hard-coded into the architecture. In a looped transformer, part of the quality can move to inference: more loops mean more FLOPs per request, but they do not require storing completely new layers. For inference engineers or system administrators, that changes how to think about the trade-off between memory, latency, and throughput.
Why this idea is gaining traction in research
OpenMythos does not appear in a vacuum. It arrives at a moment when several recent papers are pushing in exactly this direction. Loop, Think, & Generalize argues that recurrent-depth transformers can improve systematic generalization and depth extrapolation, meaning they can solve new compositions and benefit from additional implicit reasoning inside a single forward pass. Parcae, meanwhile, tackles one of the biggest historical problems of these architectures: training instability, proposing a stable parameterization of recurrent injection with spectral radius control.
The implication is important. If that line of work holds up at larger scales, depth stops being only a function of the number of trained layers and starts depending on inference-time compute as well. Parcae argues, for example, that a stable looped architecture can improve perplexity over earlier looped designs and that, under a fixed FLOP budget, looping and data should be scaled together. It is a different way of thinking about scaling: less obsession with raw parameter growth, more focus on how the same block is reused on demand.
At the same time, Relaxed Recursive Transformers adds another piece that OpenMythos explicitly incorporates: depth-wise LoRA modules. The idea is simple and powerful. The large weight matrices remain shared across iterations, but a lightweight adaptation is added per loop so the model does not become too rigid. That paper shows that this relaxation of weight tying can recover much of the original model’s performance while enabling concepts such as continuous depth-wise batching and early exiting.
What this means for developers and system administrators
For anyone deploying models, OpenMythos is interesting because it turns theoretical questions into very concrete infrastructure problems. The first is latency: if reasoning improves by increasing the number of loops, quality no longer depends only on the checkpoint but also on the inference budget assigned to each request. That means serving stacks need new controls: n_loops, early-exit policies, profiles by workload type, and cost limits per user or endpoint. The repository itself already reflects that logic by separating max_loop_iters from n_loops at execution time.
The second issue is memory planning. A weight-sharing design reduces VRAM pressure compared to stacking completely different layers, but in exchange it can increase how long a request occupies GPU resources if inference depth is raised. If MoE is added on top, the problem becomes mixed: it is not only about total parameters, but also about per-token activation patterns, expert fragmentation, and router behavior. In that part, OpenMythos clearly draws inspiration from DeepSeekMoE, whose paper argues for finely segmented experts and shared experts to improve specialization with lower compute overhead than more coarse-grained MoE designs.
The third implication affects observability and debugging. A looped model adds a complexity axis that does not exist in a fixed-depth network: it is no longer enough to inspect only layers and tokens, but also iterations. That opens the door to new production metrics: actual loop distribution, convergence per position, halting saturation, expert activation ratios, and recurrent-state stability. For MLOps or platform teams, that means different dashboards, new failure points, and another way to correlate quality with cost.

The limit: OpenMythos does not prove what Mythos is
It is important not to lose sight of the main caveat. OpenMythos does not prove the architecture of Claude Mythos Preview. What it proves is that one specific combination of ideas — RDT, MoE, MLA/GQA-style attention, stable recurrent injection, depth-wise LoRA — is now plausible and interesting enough to justify an open implementation. Anthropic has confirmed the model, published its system card, and described its restricted use in offensive and defensive security settings, but it has not confirmed that this is the technical core.
Even so, for developers and sysadmins, the value of the project is clear. OpenMythos works as a testbed for understanding why the next generation of LLMs may stop scaling only in width and start scaling in reusable depth as well. If that thesis holds, the work will no longer be just about hosting larger checkpoints, but about orchestrating more adaptive models with variable compute budgets per request. And that is a problem much closer to systems, scheduling, and serving than to simple parameter accumulation.
Frequently Asked Questions
Is OpenMythos a real leaked implementation of Claude Mythos?
No. The repository presents itself as an independent theoretical reconstruction based on public research and informed speculation, with no affiliation to Anthropic.
What technical advantage does a recurrent-depth transformer have over a standard transformer?
The core idea is to reuse the same block multiple times per pass, shifting part of scaling into inference-time compute instead of relying only on more layers or more stored parameters. Recent papers report gains in compositional generalization and scaling efficiency for this family of designs.
What operational problems does a looped architecture introduce?
Mainly variable latency, the need for early-halting mechanisms, iteration-level observability, and a more complex relationship between inference cost, quality, and throughput. If MoE is also involved, routing and expert activation add further complexity.
Has Anthropic explained how Claude Mythos Preview works internally?
No. Anthropic has published a system card and described the model as its most capable frontier model, but it has not made the detailed internal architecture public.
Source: Openmythos